SQL ストアド プロシージャの種類。 T-SQL のストアド プロシージャ - 作成、変更、削除。 SQLでストアドプロシージャを実行する方法
Microsoft SQL Server で独自のアルゴリズムを実装および自動化する ( 計算) ストアド プロシージャを使用できるので、今日はストアド プロシージャがどのように作成、変更、削除されるかについて説明します。
ただし、その前に、ストアド プロシージャとは何か、そして T-SQL でストアド プロシージャが必要な理由を理解するために、少し理論を説明します。
注記! 初心者のプログラマーには、T-SQL に関する次の役立つ資料をお勧めします。
- さらに詳しい勉強のために T-SQL言語『The T-SQL Programmer's Way』という本を読むこともお勧めします。 Transact-SQL 言語のチュートリアル。
T-SQL のストアド プロシージャとは何ですか?
ストアドプロシージャ– これらは、一連の SQL 命令の形式でアルゴリズムを含むデータベース オブジェクトです。 つまり、ストアド プロシージャはデータベース内のプログラムであると言えます。 ストアド プロシージャは、再利用可能なコードをサーバー上に保存するために使用されます。たとえば、何らかのアルゴリズム、逐次計算、または複数ステップの SQL ステートメントを作成し、そこに含まれるすべての命令を毎回実行しないようにするためです。 このアルゴリズムストアド プロシージャとしてフォーマットすることができます。 同時に、SQL プロシージャを作成すると、サーバーはコードをコンパイルします。その後、この SQL プロシージャを実行するたびに、サーバーはコードを再コンパイルしません。
SQL Server でストアド プロシージャを実行するには、その名前の前に EXECUTE コマンドを記述する必要があります。このコマンドを EXEC と省略することもできます。 たとえば、SELECT ステートメント内のストアド プロシージャを関数として呼び出すことは機能しなくなります。 手続きは別途開始されます。
ストアド プロシージャでは、関数とは異なり、UNSERT、UPDATE、DELETE などのデータ変更操作を実行することがすでに可能です。 手続きでも使えます SQL文ほぼすべてのタイプ (たとえば、テーブルを作成する CREATE TABLE または EXECUTE)。 他のプロシージャを呼び出します。 例外は、関数、ビュー、トリガーの作成または変更、スキーマの作成、およびその他の同様の命令など、いくつかの種類の命令です。たとえば、ストアド プロシージャでデータベース接続コンテキスト (USE) を切り替えることもできません。
ストアド プロシージャは入力パラメータと出力パラメータを持つことができ、表形式のデータを返すことも、何も返さず、そこに含まれる命令のみを実行することもできます。
ストアド プロシージャは非常に便利で、多くの操作を自動化または簡素化するのに役立ちます。たとえば、ピボット テーブルを使用してさまざまな複雑な分析レポートを常に生成する必要があります。 ピボット演算子。 この演算子を使用してクエリを作成しやすくするため ( ご存知のとおり、PIVOT の構文は非常に複雑です)、概要レポートを動的に生成するプロシージャを作成できます。たとえば、資料「T-SQL の動的 PIVOT」では、この機能をストアド プロシージャの形式で実装する例が示されています。
Microsoft SQL Server でのストアド プロシージャの使用例
ソースデータの例
以下のすべての例は、Microsoft SQL Server 2016 Express で実行されます。 ストアド プロシージャが実際のデータでどのように機能するかを示すには、このデータが必要です。作成しましょう。 たとえば、テスト テーブルを作成し、それにいくつかのレコードを追加してみましょう。それが製品とその価格のリストを含むテーブルであるとします。
テーブル作成命令 CREATE TABLE TestTable( INT IDENTITY(1,1) NOT NULL, INT NOT NULL, VARCHAR(100) NOT NULL, MONEY NULL) GO -- データ追加命令 INSERT INTO TestTable(CategoryId, ProductName, Price) VALUES (1 , "マウス", 100), (1, "キーボード", 200), (2, "電話", 400) GO --クエリを選択 SELECT * FROM TestTable

データが揃ったので、ストアド プロシージャの作成に進みましょう。
T-SQL でのストアド プロシージャの作成 - CREATE PROCEDURE ステートメント
ストアド プロシージャはステートメントを使用して作成されます プロシージャの作成, この指示の後に、プロシージャの名前を記述し、必要に応じて括弧内に入力パラメータと出力パラメータを定義する必要があります。 その後、あなたは書きます キーワード AS を実行し、キーワード BEGIN で命令のブロックを開き、このブロックを単語 END で閉じます。 このブロック内に、アルゴリズムまたはある種の逐次計算を実装するすべての命令を記述します。つまり、T-SQL でプログラムします。
たとえば、以下を追加するストアド プロシージャを作成してみましょう。 新しいエントリー、つまり 新製品がテストテーブルに加わりました。 これを行うには、3 つの入力パラメータを定義します。@CategoryId – 製品カテゴリ識別子、@ProductName – 製品名、@Price – このパラメータはオプションです。 それをプロシージャに渡す必要はありません ( たとえば、価格はまだわかりません)、この目的のために、その定義にデフォルト値を設定します。 これらのパラメータはプロシージャの本体内にあります。 通常の変数と同じように、BEGIN…END ブロック内で使用できます ( ご存知のとおり、変数は @ 記号で表されます。)。 出力パラメータを指定する必要がある場合は、パラメータ名の後にキーワード OUTPUT ( または略してOUT).
BEGIN...END ブロックには、データを追加する命令と、プロシージャの最後に SELECT 命令を記述します。これにより、ストアド プロシージャが製品に関する表形式のデータを返します。 指定されたカテゴリ追加されたばかりの新しい製品を考慮して。 また、このストアド プロシージャでは、複数のスペースが誤って入力される状況を排除するために、入力パラメータの処理、つまり文字列の先頭と末尾の余分なスペースを削除する処理を追加しました。
この手順のコードは次のとおりです ( 私もそれについてコメントしました).
プロシージャの作成 CREATE PROCEDURE TestProcedure (--入力パラメータ @CategoryId INT, @ProductName VARCHAR(100), @Price MONEY = 0) AS BEGIN --アルゴリズムを実装する命令 --受信パラメータの処理 --先頭の余分なスペースを削除そしてテキスト行の最後に SET @ProductName = LTRIM(RTRIM(@ProductName));

-- 新しいレコードを追加します INSERT INTO TestTable(CategoryId, ProductName, Price) VALUES (@CategoryId, @ProductName, @Price) -- データを返します SELECT * FROM TestTable WHERE CategoryId = @CategoryId END GO
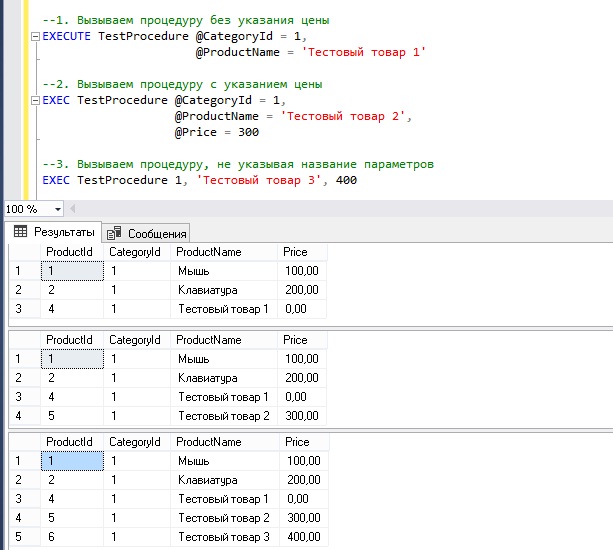
T-SQL でのストアド プロシージャの実行 - EXECUTE コマンド すでに述べたように、EXECUTE または EXEC コマンドを使用してストアド プロシージャを実行できます。 受信パラメータは、それらをリストし、プロシージャ名の後に適切な値を指定するだけでプロシージャに渡されます (出力パラメータの場合は、OUTPUT コマンドも指定する必要があります。 )。 ただし、パラメータの名前を指定しないこともできますが、この場合は、値を指定する順序に従う必要があります。 入力パラメータが定義されている順序で値を指定します().
これは出力パラメータにも当てはまります
デフォルト値を持つパラメータは指定する必要はありません。これらはいわゆるオプションのパラメータです。
1. 価格を指定せずにプロシージャを呼び出します。 EXECUTE TestProcedure @CategoryId = 1, @ProductName = "Test product 1" --2. 価格を示すプロシージャ EXEC TestProcedure @CategoryId = 1, @ProductName = "Test product 2", @Price = 300 --3 を呼び出します。 パラメータ名を指定せずにプロシージャを呼び出します。 EXEC TestProcedure 1, "Test product 3", 400
ストアド プロシージャを T-SQL に変更する - ALTER PROCEDURE ステートメント
手順を使用して手順のアルゴリズムを変更できます。 手順の変更。 つまり、既存のプロシージャを変更するには、CREATE PROCEDURE の代わりに ALTER PROCEDURE を記述し、必要に応じて他のすべてを変更するだけです。
テスト手順、たとえば @Price パラメータを変更する必要があるとします。 価格を必須にします。このためにデフォルト値を削除し、結果のデータセットを取得する必要がなくなったと想定します。このために、単純にストアドプロシージャから SELECT ステートメントを削除します。
プロシージャ ALTER PROCEDURE TestProcedure (--受信パラメータ @CategoryId INT, @ProductName VARCHAR(100), @Price MONEY) AS BEGIN --アルゴリズムを実装する命令 --受信パラメータの処理 --先頭の余分なスペースを削除し、テキスト行の終わり SET @ProductName = LTRIM(RTRIM(@ProductName));
-- 新しいレコードを追加します INSERT INTO TestTable(CategoryId, ProductName, Price) VALUES (@CategoryId, @ProductName, @Price) END GO
T-SQL でのストアド プロシージャの削除 - DROP PROCEDURE ステートメント 必要に応じて、手順に従ってストアド プロシージャを削除できます。.
ドロップ手順
たとえば、作成したテスト プロシージャを削除してみましょう。
DROP PROCEDURE テスト手順
ストアド プロシージャを削除する場合、そのプロシージャが他のプロシージャまたは SQL ステートメントによって参照されている場合、それらが参照するプロシージャはもう存在しないため、削除後にエラーが発生して失敗することに注意してください。
私が持っているのはこれだけです。この資料が興味深く、お役に立てば幸いです、さようなら!
ストアド プロシージャがクエリのパフォーマンスを低下させる可能性がある状況を考慮します。
MS SQL Server 2000 でストアド プロシージャをコンパイルすると、ストアド プロシージャはプロシージャ キャッシュに配置されます。これにより、ストアド プロシージャのコードを解析、最適化、コンパイルする必要がなくなり、ストアド プロシージャの実行時のパフォーマンスが向上します。 落とし穴逆効果になる可能性があります。
実際、ストアド プロシージャをコンパイルすると、プロシージャ コードを構成するステートメントの実行計画もそれに応じてコンパイルされます。コンパイルされたストアド プロシージャがキャッシュされる場合、その実行計画もキャッシュされるため、ストアド プロシージャはキャッシュされません。特定の状況とクエリパラメータに合わせて最適化されます。
これを証明するためにちょっとした実験をしてみましょう。
ステップ1。 データベースの作成。
実験のために、別のデータベースを作成します。
データベースの作成 test_sp_perf
ON (NAME="test_data"、FILENAME="c:\temp\test_data"、SIZE=1、MAXSIZE=10、FILEGROWTH=1Mb)
ログオン (NAME="test_log"、FILENAME="c:\temp\test_log"、SIZE=1、MAXSIZE=10、FILEGROWTH=1Mb)
ステップ2.テーブルの作成。
CREATE TABLE sp_perf_test(column1 int, column2 char(5000))
ステップ3.テーブルにテスト行を埋め込みます。 重複行は意図的にテーブルに追加されます。 1 から 10,000 までの番号が 10,000 行、50,000 までの番号が 10,000 行あります。
@i int を宣言
SET @i=1
WHILE(@i<10000)
始める
INSERT INTO sp_perf_test(column1, column2) VALUES(@i,"テスト文字列 #"+CAST(@i as char(8)))
INSERT INTO sp_perf_test(column1, column2) VALUES(50000,"テスト文字列 #"+CAST(@i as char(8)))
SET @i= @i+1
終わり
sp_perf_test から SELECT COUNT(*)
行く
ステップ4.非クラスター化インデックスを作成します。 実行計画はプロシージャとともにキャッシュされるため、インデックスはすべての呼び出しで同じように使用されます。
sp_perf_test(column1) に非クラスター化インデックス CL_perf_test を作成します
行く
ステップ5.ストアド プロシージャを作成します。 このプロシージャは、条件を指定して SELECT ステートメントを実行するだけです。
CREATE PROC proc1 (@param int)
として
SELECT 列 1、列 2 FROM sp_perf_test WHERE 列 1=@param
行く
ステップ6.ストアド プロシージャを実行しています。 脆弱なプロシージャを実行する場合、選択パラメータが特別に使用されます。 手順の結果、1 行が得られます。 実行プランでは、非クラスター化インデックスの使用が示されています。 クエリは選択的であり、これが行を取得する最良の方法です。 単一行をフェッチするように最適化されたプロシージャは、プロシージャ キャッシュに格納されます。
EXEC 手続き 1 1234
行く
ステップ7。非選択パラメータを使用してストアド プロシージャを実行します。 パラメーターとして使用される値は 50000 です。最初の列にはこの値を持つ行が約 10000 行あります。したがって、非クラスター化インデックスの使用とブックマーク検索操作は効果的ではありませんが、実行プランを含むコンパイルされたコードは に保存されます。手続き型キャッシュ、これが使用されるものです。 実行計画には、これと、ブックマーク検索操作が 9999 行に対して実行されたという事実が示されています。
EXEC proc1 50000
行く

ステップ8.最初のフィールドが 50000 に等しい行の選択を実行します。別のクエリを実行する場合、クエリは最適化され、最初の列の特定の値でコンパイルされます。 その結果、クエリ オプティマイザーはフィールドが何度も重複していると判断し、テーブル スキャン操作を使用することを決定します。 この場合非クラスター化インデックスを使用するよりもはるかに効率的です。
SELECT 列 1、列 2 FROM sp_perf_test WHERE 列 1=50000
行く

したがって、ストアド プロシージャを使用してもクエリのパフォーマンスが必ずしも向上するとは限らないと結論付けることができます。 可変行数の結果を操作し、異なる実行プランを使用するストアド プロシージャについては、細心の注意を払う必要があります。
スクリプトを使用して、MS SQL サーバー上で実験を繰り返すことができます。
ストアド プロシージャの作成と呼び出しの例が示されています。
ストアドプロシージャストアド プロシージャの概念 相互接続された SQL ステートメントのグループであり、これを使用するとプログラマの作業がより簡単かつ柔軟になります。ストアドプロシージャ 多くの場合、一連の個別の SQL ステートメントよりもはるかに単純です。 ストアド プロシージャは、1 つ以上の SQL ステートメントまたは関数で構成され、コンパイルされた形式でデータベースに保存される一連のコマンドです。 データベース内での実行ストアドプロシージャ
- 個々の SQL ステートメントの代わりに、ユーザーには次の利点があります。
- 必要な演算子はすでにデータベースに含まれています。 彼らは全員ステージを通過しました解析する 実行可能形式です。 前にストアド プロシージャの実行
- SQL Server は実行プランを生成し、最適化とコンパイルを実行します。ストアドプロシージャ サポート大きなタスクを独立した、より小さく、管理しやすい部分に分割できるためです。
- SQL Server は実行プランを生成し、最適化とコンパイルを実行します。他の人に影響を与える可能性があります SQL Server は実行プランを生成し、最適化とコンパイルを実行します。および機能。
- SQL Server は実行プランを生成し、最適化とコンパイルを実行します。他の種類のアプリケーション プログラムから呼び出すことができます。
- 原則として、 SQL Server は実行プランを生成し、最適化とコンパイルを実行します。個々のステートメントのシーケンスよりも高速に実行されます。
- SQL Server は実行プランを生成し、最適化とコンパイルを実行します。使いやすい: コマンドは数十または数百のコマンドで構成できますが、実行するには目的のコマンドの名前を指定するだけです。 ストアドプロシージャ。 これにより、クライアントからサーバーに送信されるリクエストのサイズが軽減され、ネットワークの負荷が軽減されます。
プロシージャを実行する場所と同じ場所に保存すると、ネットワーク上で転送されるデータ量が削減され、システム全体のパフォーマンスが向上します。 応用 多くの場合、一連の個別の SQL ステートメントよりもはるかに単純です。 ストアド プロシージャは、1 つ以上の SQL ステートメントまたは関数で構成され、コンパイルされた形式でデータベースに保存される一連のコマンドです。 データベース内での実行ソフトウェア システムのメンテナンスと変更が簡素化されます。 通常、ルールとデータ処理アルゴリズムの形式のすべての整合性制約はデータベース サーバーに実装され、セットとしてエンド アプリケーションで利用できます。 多くの場合、一連の個別の SQL ステートメントよりもはるかに単純です。 ストアド プロシージャは、1 つ以上の SQL ステートメントまたは関数で構成され、コンパイルされた形式でデータベースに保存される一連のコマンドです。 データベース内での実行、データ処理インターフェイスを表します。 データの整合性を確保するため、またセキュリティ目的のため、アプリケーションは通常、データへの直接アクセスを受け取りません。データを扱うすべての作業は、特定のメソッドを呼び出すことによって実行されます。 多くの場合、一連の個別の SQL ステートメントよりもはるかに単純です。 ストアド プロシージャは、1 つ以上の SQL ステートメントまたは関数で構成され、コンパイルされた形式でデータベースに保存される一連のコマンドです。 データベース内での実行.
このアプローチにより、データ処理アルゴリズムの変更が非常に簡単になり、すべてのネットワーク ユーザーがすぐに利用できるようになり、アプリケーション自体に変更を加えずにシステムを拡張できるようになります。 ストアドプロシージャデータベースサーバー上で。 開発者は、アプリケーションを再コンパイルしたり、そのコピーを作成したり、新しいバージョンで作業するようにユーザーに指示したりする必要はありません。 ユーザーは、システムに変更が加えられたことにさえ気づいていない可能性があります。
ストアドプロシージャテーブルや他のデータベース オブジェクトとは独立して存在します。 これらはクライアント プログラムによって呼び出されます。 ストアドプロシージャまたはトリガー。 開発者はアクセス権を管理できます。 ストアドプロシージャ、その実行を許可または禁止します。 コードを変更する ストアドプロシージャ所有者または固定データベース ロールのメンバーのみが許可されます。 必要に応じて、その所有権をあるユーザーから別のユーザーに譲渡できます。
MS SQL Server環境のストアドプロシージャ
SQL Server を使用する場合、ユーザーは特定のアクションを実装する独自のプロシージャを作成できます。 ストアドプロシージャは本格的なデータベース オブジェクトであるため、それぞれが特定のデータベースに保存されます。 直接電話 ストアドプロシージャプロシージャが配置されているデータベースのコンテキストで実行される場合にのみ可能です。
ストアド プロシージャの種類
SQL Serverにはいくつかの種類があります 多くの場合、一連の個別の SQL ステートメントよりもはるかに単純です。 ストアド プロシージャは、1 つ以上の SQL ステートメントまたは関数で構成され、コンパイルされた形式でデータベースに保存される一連のコマンドです。 データベース内での実行.
- システム SQL Server は実行プランを生成し、最適化とコンパイルを実行します。さまざまな管理アクションを実行するように設計されています。 ほとんどすべてのサーバー管理活動は、彼らの助けを借りて実行されます。 システム的に言えることは、 SQL Server は実行プランを生成し、最適化とコンパイルを実行します。はシステム テーブルの操作を提供するインターフェイスであり、最終的にはユーザー データベースとシステム データベースの両方のシステム テーブルからのデータの変更、追加、削除、取得を行います。 システム ストアドプロシージャ sp_ プレフィックスが付いており、システム データベースに保存され、他のデータベースのコンテキストで呼び出すことができます。
- カスタム SQL Server は実行プランを生成し、最適化とコンパイルを実行します。特定のアクションを実行します。 ストアドプロシージャ– 本格的なデータベース オブジェクト。 その結果、それぞれの ストアドプロシージャ実行される特定のデータベースに配置されます。
- 一時的 SQL Server は実行プランを生成し、最適化とコンパイルを実行します。一時的にのみ存在し、その後はサーバーによって自動的に破棄されます。 それらはローカルとグローバルに分けられます。 ローカル一時的 SQL Server は実行プランを生成し、最適化とコンパイルを実行します。作成された接続からのみ呼び出すことができます。 このようなプロシージャを作成するときは、単一の # 文字で始まる名前を付ける必要があります。 すべての一時的なオブジェクトと同様に、 SQL Server は実行プランを生成し、最適化とコンパイルを実行します。このタイプのファイルは、ユーザーが切断されるか、サーバーが再起動または停止されると自動的に削除されます。 グローバルテンポラリ ストアドプロシージャ同じ手順を持つサーバーからのすべての接続で利用できます。 これを定義するには、文字 ## で始まる名前を付けるだけです。 これらのプロシージャは、サーバーが再起動または停止されるとき、またはプロシージャが作成されたコンテキスト内の接続が閉じられるときに削除されます。
ストアド プロシージャの作成、変更、削除
創造 ストアドプロシージャ次の問題を解決する必要があります。
- 作成されたタイプの決定 ストアドプロシージャ: 一時的またはカスタム。 さらに、独自のシステムを作成することもできます 相互接続された SQL ステートメントのグループであり、これを使用するとプログラマの作業がより簡単かつ柔軟になります。、sp_ という接頭辞を付けた名前を付けて、システム データベースに配置します。 この手順は、任意のローカル サーバー データベースのコンテキストで使用できます。
- アクセス権の計画。 作成時 ストアドプロシージャデータベース オブジェクトに対して、それを作成したユーザーと同じアクセス権を持つことを考慮する必要があります。
- 意味 ストアド プロシージャのパラメータ。 ほとんどのプログラミング言語に含まれるプロシージャと同様に、 ストアドプロシージャ入力パラメータと出力パラメータがある場合があります。
- コード開発 ストアドプロシージャ。 プロシージャ コードには、他の SQL コマンドの呼び出しを含む、一連の SQL コマンドを含めることができます。 ストアドプロシージャ.
新しいものを作成し、既存のものを変更する ストアドプロシージャ次のコマンドを使用して実行します。
<определение_процедуры>::= (CREATE | ALTER ) PROC プロシージャ名 [;番号] [(@パラメータ名 データ型 ) [=デフォルト] ][,...n] AS sql_operator [...n]
このコマンドのパラメータを見てみましょう。
接頭辞 sp_ 、 # 、 ## を使用すると、作成されたプロシージャをシステムまたは一時的なプロシージャとして定義できます。 コマンド構文からわかるように、作成されたプロシージャを所有する所有者の名前や、プロシージャを配置するデータベースの名前を指定することはできません。 したがって、作成したものを配置するには、 ストアドプロシージャ特定のデータベースでは、そのデータベースのコンテキストで CREATE PROCEDURE コマンドを発行する必要があります。 本体から回転する場合 ストアドプロシージャ短縮名は、同じデータベースのオブジェクトに対して、つまりデータベース名を指定せずに使用できます。 他のデータベースにあるオブジェクトにアクセスする必要がある場合は、データベース名の指定が必須です。
名前の数字は識別番号です ストアドプロシージャ、プロシージャのグループ内でそれを一意に識別します。 管理を容易にするため、プロシージャは論理的に同じタイプになります。 SQL Server は実行プランを生成し、最適化とコンパイルを実行します。同じ名前で異なる識別番号を与えることでグループ化できます。
作成した入力データと出力データを転送するには ストアドプロシージャパラメータを使用できますが、その名前はローカル変数の名前と同様に @ 記号で始まる必要があります。 1つで ストアドプロシージャ複数のパラメータをカンマで区切って指定できます。 プロシージャの本体では、このプロシージャのパラメータの名前と名前が一致するローカル変数を使用しないでください。
対応するデータ型を判断するには、 ストアド プロシージャのパラメータ、ユーザー定義のものを含むあらゆる SQL データ型が適しています。 ただし、CURSOR データ型は次のようにのみ使用できます。 出力パラメータ ストアドプロシージャ、つまり OUTPUT キーワードを指定します。
OUTPUT キーワードの存在は、対応するパラメータがデータを返すことを意図していることを意味します。 ストアドプロシージャ。 ただし、これはパラメータが値を渡すのに適していないという意味ではありません。 相互接続された SQL ステートメントのグループであり、これを使用するとプログラマの作業がより簡単かつ柔軟になります。。 OUTPUT キーワードを指定すると、サーバーに終了が指示されます。 ストアドプロシージャパラメータの現在の値を、プロシージャの呼び出し時にパラメータの値として指定したローカル変数に割り当てます。 OUTPUT キーワードを指定する場合、プロシージャを呼び出すときの対応するパラメーターの値は、ローカル変数を使用してのみ設定できることに注意してください。 通常のパラメータに許可されている式や定数の使用は許可されません。
VARYING キーワードは、CURSOR 型の OUTPUT パラメータと組み合わせて使用されます。 それは次のことを決定します 出力パラメータ結果セットが存在します。
DEFAULT キーワードは、対応する値を表します。 デフォルトパラメータ。 したがって、プロシージャを呼び出すときに、対応するパラメータの値を明示的に指定する必要はありません。
サーバーはクエリ実行プランとコンパイルされたコードをキャッシュするため、次回プロシージャが呼び出されるときは、既製の値が使用されます。 ただし、場合によっては、プロシージャ コードを再コンパイルする必要がある場合もあります。 RECOMPILE キーワードを指定すると、システムに実行計画を作成するように指示されます。 ストアドプロシージャ彼女が電話するたびに。
FOR REPLICATION パラメータは、データをレプリケートし、作成されたデータを有効にする場合に必要です。 ストアドプロシージャ出版用の記事として。
ENCRYPTION キーワードは、サーバーにコードを暗号化するように指示します。 ストアドプロシージャ、作業を実装する独自のアルゴリズムの使用に対する保護を提供できます。 ストアドプロシージャ.
AS キーワードは本文自体の先頭に配置されます ストアドプロシージャ、つまり これまたはそのアクションを実装するための一連の SQL コマンド。 ほとんどすべての SQL コマンドをプロシージャ本体で使用でき、トランザクションを宣言したり、ロックを設定したり、その他のコマンドを呼び出すことができます。 SQL Server は実行プランを生成し、最適化とコンパイルを実行します。。 から出る ストアドプロシージャ RETURNコマンドを使用して実行できます。
ストアド プロシージャの削除次のコマンドによって実行されます。
DROP PROCEDURE (プロシージャ名) [,...n]
ストアド プロシージャの実行
のために ストアド プロシージャを実行する使用されるコマンドは次のとおりです。
[[ EXEC [ UTE] プロシージャ名 [;番号] [[@パラメータ名=](値 | @変数名) |][,...n]
電話の場合 ストアドプロシージャパッケージ内のコマンドはこれだけではないため、EXECUTE コマンドが存在する必要があります。 さらに、このコマンドは、別のプロシージャまたはトリガーの本体からプロシージャを呼び出すために必要です。
プロシージャを呼び出すときの OUTPUT キーワードの使用は、次のときに宣言されたパラメータに対してのみ許可されます。 プロシージャの作成 OUTPUT キーワードを使用します。
プロシージャを呼び出すときにパラメータにキーワード DEFAULT が指定されている場合、それが使用されます。 デフォルト値。 当然のことながら、指定された単語 DEFAULT は、それが定義されているパラメーターに対してのみ許可されます。 デフォルト値.
EXECUTE コマンドの構文は、プロシージャを呼び出すときにパラメータ名を省略できることを示しています。 ただし、この場合、ユーザーはパラメータの値を、パラメータの値を指定するときにリストされたのと同じ順序で指定する必要があります。 プロシージャの作成。 パラメータへの割り当て デフォルト値、出品時にスキップすることはできません。 定義されているパラメータを省略したい場合 デフォルト値を呼び出すときにパラメータ名を明示的に指定するだけで十分です。 ストアドプロシージャ。 さらに、この方法では、パラメータとその値を任意の順序でリストできます。
プロシージャを呼び出すときは、値を含むパラメータ名、またはパラメータ名のない値のみを指定することに注意してください。 これらを組み合わせることはできません。
例12.1。 パラメータのないプロシージャ。 イワノフが購入した商品の名前と価格を取得する手順を作成します。
CREATE PROC my_proc1 AS SELECT Product.Name、Product.Price*Transaction.Quantity AS Cost、Customer.Last Name FROM Customer INNER JOIN (Product INNER JOIN Transaction ON Product.ProductCode=Transaction.ProductCode) ON Customer.CustomerCode=Transaction.CustomerCode WHERE顧客 .Last name='イワノフ' 例12.1。
のために イワノフが購入した商品の名前と価値を取得する手順。手続きへのアクセス
次のコマンドを使用できます。
EXEC my_proc1 または my_proc1
このプロシージャはデータセットを返します。 パラメータのないプロシージャ例12.2。
のために イワノフが購入した商品の名前と価値を取得する手順。手続きへのアクセス
。 第一級品の価格を10%引き下げる手順を作成します。
EXEC my_proc2 または my_proc2
このプロシージャはデータを返しません。 例12.3。入力パラメータを使用したプロシージャ
。 特定の顧客が購入した商品の名前と価格を取得するプロシージャを作成します。 CREATE PROC my_proc3 @k VARCHAR(20) AS SELECT Product.Name、Product.Price*Transaction.Quantity AS Cost、Customer.Last Name FROM Customer INNER JOIN (Product INNER JOIN Deal ON Product.ProductCode=Transaction.ProductCode) ON Customer。 CustomerCode =Transaction.ClientCode WHERE Client.LastName=@k
のために イワノフが購入した商品の名前と価値を取得する手順。手続きへのアクセス
例12.3。
特定の顧客が購入した商品の名前と価格を取得する手順。 EXEC my_proc3 "Ivanov" または my_proc3 @k="Ivanov"
のために イワノフが購入した商品の名前と価値を取得する手順。手続きへのアクセス
例12.4。
。 指定されたタイプの製品の価格を、指定された%に従って値下げするプロシージャを作成します。 EXEC my_proc4 "ワッフル",0.05 または EXEC my_proc4 @t="ワッフル", @p=0.05例12.5。
入力パラメータを使用したプロシージャ およびデフォルト値。 指定されたタイプの製品の価格を、指定された%に従って値下げするプロシージャを作成します。
のために イワノフが購入した商品の名前と価値を取得する手順。手続きへのアクセス
CREATE PROC my_proc5 @t VARCHAR(20)=’Candy`, @p FLOAT=0.1 AS UPDATE Product SET Price=Price*(1-@p) WHERE Type=@t
この場合、キャンディーの価格が減額されます (プロシージャを呼び出すときに型の値は指定されず、デフォルトで使用されます)。
後者の場合、プロシージャを呼び出すときに両方のパラメータ (タイプとパーセンテージの両方) が指定されず、それらの値がデフォルトで取得されます。
例12.6。 入力パラメータと出力パラメータを使用したプロシージャ。 特定の月に販売された商品の総原価を決定するプロシージャを作成します。
CREATE PROC my_proc6 @m INT, @s FLOAT OUTPUT AS SELECT @s=Sum(Product.Price*Transaction.Quantity) FROM Product INNER JOIN Transaction ON Product.ProductCode=Transaction.ProductCode GROUP BY Month(Transaction.Date) HAVING Month(トランザクション.日付)=@m 例12.6。 入力パラメータと出力パラメータを使用するプロシージャ。 特定の月に販売された商品の総原価を決定するプロシージャを作成します。
のために イワノフが購入した商品の名前と価値を取得する手順。手続きへのアクセス
DECLARE @st FLOAT EXEC my_proc6 1,@st OUTPUT SELECT @st
このコマンド ブロックを使用すると、1 月に販売された商品の原価を決定できます ( 入力パラメータ月は 1) として指定されます。
特定の従業員が勤務する会社が購入した商品の合計数量を決定する手順を作成します。
まず、従業員が勤務する会社を決定する手順を作成します。
例12.7。使用法 ネストされたプロシージャ。 特定の従業員が勤務する会社が購入した商品の合計数量を決定する手順を作成します。
次に、関心のある会社が購入した商品の合計数量を計算するプロシージャを作成します。
CREATE PROC my_proc8 @fam VARCHAR(20), @kol INT OUTPUT AS DECLARE @firm VARCHAR(20) EXEC my_proc7 @fam,@firm OUTPUT SELECT @kol=Sum(Transaction.Quantity) FROM Client INNER JOIN Transaction ON Client.ClientCode= Transaction.ClientCode GROUP BY Client.Firm HAVING Client.Company=@firm 例12.7。 特定の従業員が勤務する会社が購入した商品の合計数量を決定する手順を作成します。
このプロシージャは、次のコマンドを使用して呼び出されます。
DECLARE @k INT EXEC my_proc8 ‘Ivanov’,@k OUTPUT SELECT @k
手続き宣言
プロシージャの作成 [({入力|出力|入力} [,…])]
[動的結果セット ]
始める [アトミック]
終わり
キーワード
。 IN (入力) – 入力パラメータ
。 OUT (出力) – 出力パラメータ
。 INOUT – 入力と出力、およびフィールド (パラメーターなし)
。 DYNAMIC RESULT SET は、プロシージャが指定された数のカーソルを開くことができ、プロシージャが戻った後も開いたままになることを示します。
注意事項
ネットワークとスタックの過負荷のため、ストアド プロシージャで多くのパラメーター (主に大きな数値と文字列) を使用することはお勧めできません。 実際には、Transact-SQL、PL/SQL、および Informix の既存の方言には、パラメータの宣言と使用、変数の宣言、およびサブルーチンの呼び出しの両方において、標準とは大きな違いがあります。 Microsoft では、次の近似値を使用してストアド プロシージャのキャッシュ サイズを見積もることをお勧めします。
=(同時ユーザーの最大数)*(最大実行プランのサイズ)*1.25。 実行プランのページ単位のサイズは、DBCC MEMUSAGE コマンドを使用して決定できます。
プロシージャの呼び出し
多くの既存の DBMS では、ストアド プロシージャは次の演算子を使用して呼び出されます。
手順の実行 [(][)]
注記: ストアド プロシージャの呼び出しは、アプリケーション内、別のストアド プロシージャ内から、または対話的に行うことができます。
プロシージャ宣言の例
CREATE PROCEDURE Proc1 AS //プロシージャを宣言
DECLARE Cur1 CURSOR FOR SELECT SName, City FROM SalesPeople WHERE Rating>200 // カーソルを宣言します
OPEN Cur1 //カーソルをオープンします
FETCH NEXT FROM Cur1 //カーソルからデータを読み取ります
WHILE @@Fetch_Status=0
始める
Cur1 から次をフェッチ
終わり
CLOSE Cur1 //カーソルを閉じる
DEALLOCATE Cur1
EXECUTE Proc1 //プロシージャを実行します
ポリモーフィズム
2 つのサブルーチンのパラメータが区別できるほど互いに十分に異なっている場合、同じ名前の 2 つのサブルーチンを同じスキーマ内に作成できます。 同じスキーマ内の同じ名前を持つ 2 つのルーチンを区別するために、それぞれに代替の一意の名前 (特定の名前) が与えられます。 このような名前は、サブルーチンを定義するときに明示的に指定できます。 複数の同じ名前を持つサブルーチンを呼び出す場合、必要なサブルーチンの決定はいくつかの手順で実行されます。
。 最初に、指定された名前を持つすべてのプロシージャが定義され、何もない場合は、指定された名前を持つすべての関数が定義されます。
。 さらなる分析のために、どのサブルーチンに関連するもののみが表示されます。 このユーザー実行権限(EXECUTE)を持ちます。
。 これらについては、呼び出し引数の数に対応するパラメータの数を持つものが選択されます。 チェックされています 指定されたタイプパラメータとその位置に関するデータ。
。 複数のサブルーチンが残っている場合は、修飾名が短いものが選択されます。
実際には、Oracle ではポリモーフィズムはパッケージ内で宣言された関数に対してのみサポートされ、DB@ - 異なるスキーマ内でのみサポートされ、Sybase と MS SQL Server ではオーバーロードが禁止されています。
削除・変更手続き
プロシージャを削除するには、次の演算子を使用します。
プロシージャを変更するには、次の演算子を使用します。
手順の変更 [([{入力|出力|入力}])]
始める [アトミック]
終わり
手順を実行する権限
実行許可を与える に |公共 [付与オプションあり]
システム手順
多くの DBMS (SQL Server を含む) には、独自の目的に使用できる特定の組み込みシステム ストアド プロシージャ セットが備わっています。
SQL - レッスン 15. ストアド プロシージャ。 パート 1。
原則として、データベースを操作するときは、同じクエリまたは一連の連続クエリを使用します。 ストアド プロシージャを使用すると、一連のクエリを結合してサーバーに保存できます。 これはとても 便利なツール, すると、これが表示されます。 構文から始めましょう:CREATE PROCEDURE プロシージャ名 (パラメータ) begin ステートメント end
パラメーターはプロシージャが呼び出されたときにプロシージャに渡すデータであり、演算子はリクエストそのものです。 最初のプロシージャを作成して、それが便利であることを確認してみましょう。 レッスン 10 では、ショップ データベースに新しいレコードを追加するときに、標準クエリを使用してフォームを追加しました。
INSERT INTO 顧客 (名前、電子メール) VALUE ("Ivanov Sergey", " [メールで保護されています]");
なぜなら 新しい顧客を追加する必要があるたびに同様のリクエストを使用するため、手順の形式で形式化することが非常に適切です。
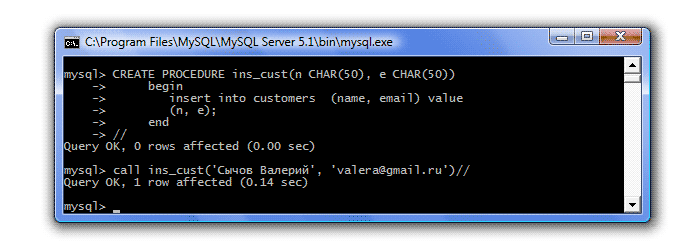
CREATE PROCEDURE ins_cust(n CHAR(50), e CHAR(50)) begin insert into Customers (name, email) value (n, e);
終わり 
パラメータの指定方法に注意してください。パラメータに名前を付け、そのタイプを示す必要があります。プロシージャの本体ではすでにパラメータ名が使用されています。 注意点が 1 つあります。 ご存知のとおり、セミコロンはリクエストの終わりを意味し、リクエストを実行のために送信しますが、この場合は受け入れられません。 したがって、プロシージャを作成する前に、c セパレータを再定義する必要があります。 リクエストが事前に送信されないように、「//」に変更します。 これは DELIMITER // 演算子を使用して行われます。
したがって、コマンドは // の後に実行する必要があることを DBMS に指示しました。 セパレータの再定義は 1 つのセッションに対してのみ実行されることに注意してください。 次回 MySql を使用するとき、区切り文字は再びセミコロンになるため、必要に応じて再定義する必要があります。 これで、プロシージャを配置できます。

これで手順が作成されました。 新しい顧客を入力する必要がある場合は、必要なパラメータを指定してそれを呼び出すだけです。 ストアド プロシージャを呼び出すには、CALL ステートメントを使用し、その後にプロシージャの名前とそのパラメータを続けます。 新しい顧客を Customers テーブルに追加しましょう。
call ins_cust("サイコフ・ヴァレリー", " [メールで保護されています]")//
毎回書くよりもずっと簡単だということに同意する 完全なリクエスト。 Customers テーブルに新しい顧客が表示されているかどうかを確認して、手順が機能するかどうかを確認してみましょう。

表示され、プロシージャは機能し、演算子を使用して削除するまで常に機能します。 DROP PROCEDURE プロシージャ名.
レッスンの冒頭で述べたように、プロシージャを使用すると、一連のクエリを組み合わせることができます。 それがどのように行われるかを見てみましょう。 レッスン 11 で、サプライヤー「House of Printing」が商品を持ち込んでくれた金額を知りたかったのを覚えていますか? これを行うには、サブクエリ、結合、計算列、ビューを使用する必要がありました。 他のサプライヤーが商品をいくらで持ってきたのか知りたい場合はどうすればよいでしょうか? 新しいクエリや結合などを作成する必要があります。 このアクションのストアド プロシージャを一度作成しておくと簡単です。
最も簡単な方法は、レッスン 11 で既に記述したビューを取得してクエリを実行し、それをストアド プロシージャに結合して、次のようにベンダー識別子 (id_vendor) を入力パラメータにすることだと思われます。
CREATE PROCEDURE sum_vendor(i INT) begin CREATE VIEW report_vendor AS SELECTmagazine_incoming.id_product,magazine_incoming.quantity,price.price,magazine_incoming.quantity*prices.price AS summa FROMmagazine_incoming,price WHEREmagazine_incoming.id_product=price.id_product AND id_incoming= ( SELECT id_incoming FROM incoming WHERE id_vendor=i);
SELECT SUM(合計) FROM レポートベンダー; 終わり //しかし、この手順はそのようには機能しません。 要点は次のとおりです
CREATE VIEW report_vendor AS SELECT incoming.id_vendor、magazine_incoming.id_product、magazine_incoming.quantity、price.price、magazine_incoming.quantity*prices.price AS summa FROM incoming、magazine_incoming、price WHEREmagazine_incoming.id_product=price.id_product ANDmagazine_incoming.id_incoming=incoming .id_受信;
次に、関心のあるサプライヤーの供給量を合計するクエリを作成します (たとえば、id_vendor=2)。
ここで、これら 2 つのクエリをストアド プロシージャに結合できます。入力パラメータはベンダー識別子 (id_vendor) になり、2 番目のクエリには代入されますが、ビューには代入されません。
CREATE PROCEDURE sum_vendor(i INT) begin CREATE VIEW report_vendor AS SELECT incoming.id_vendor、magazine_incoming.id_product、magazine_incoming.quantity、price.price、magazine_incoming.quantity*prices.price AS summa FROM incoming、magazine_incoming、prices WHEREmagazine_incoming.id_product=prices .id_product ANDmagazine_incoming.id_incoming= incoming.id_incoming;

SELECT SUM(合計) FROM report_vendor WHERE id_vendor=i;

終わり //
さまざまな入力パラメータを使用してプロシージャの動作を確認してみましょう。
ご覧のとおり、このプロシージャは 1 回実行された後、エラーをスローして、report_vendor ビューがデータベースにすでに存在していることを示します。 これは、プロシージャが初めて呼び出されたときにビューが作成されるためです。 2 回目にアクセスすると、ビューを再度作成しようとしますが、ビューはすでに存在しているため、エラーが表示されます。 これを回避するには 2 つのオプションがあります。

1 つ目は、手続きから表現を取り除くことです。 つまり、ビューを一度作成すると、プロシージャはビューにアクセスするだけで、作成はしません。 作成済みのプロシージャを削除して最初に表示することを忘れないでください。
DROP PROCEDURE sum_vendor// DROP VIEW report_vendor// CREATE VIEW report_vendor AS SELECT incoming.id_vendor、magazine_incoming.id_product、magazine_incoming.quantity、price.price、magazine_incoming.quantity*prices.price AS summa FROM incoming、magazine_incoming、prices WHEREmagazine_incoming.id_product =price.id_product ANDmagazine_incoming.id_incoming= incoming.id_incoming // CREATE PROCEDURE sum_vendor(i INT) begin SELECT SUM(summa) FROM report_vendor WHERE id_vendor=i;

終わり //
CREATE PROCEDURE sum_vendor(i INT) begin DROP VIEW IF EXISTS report_vendor;
CREATE VIEW report_vendor AS SELECT incoming.id_vendor、magazine_incoming.id_product、magazine_incoming.quantity、price.price、magazine_incoming.quantity*prices.price AS summa FROM incoming、magazine_incoming、price WHEREmagazine_incoming.id_product=price.id_product ANDmagazine_incoming.id_incoming=incoming .id_受信; 
SELECT SUM(合計) FROM report_vendor WHERE id_vendor=i;
-
 2015 年 4 月 17 日終わり //
2015 年 4 月 17 日終わり // -
 2015 年 4 月 17 日このオプションを使用する前に、必ず sum_vendor プロシージャを削除してから、作業をテストしてください。
2015 年 4 月 17 日このオプションを使用する前に、必ず sum_vendor プロシージャを削除してから、作業をテストしてください。 -
 2015 年 4 月 17 日Yandexで無料でファイルを保存するためのクラウドを作成する方法
2015 年 4 月 17 日Yandexで無料でファイルを保存するためのクラウドを作成する方法

")




