Python で独自のニューラル ネットワークを最初から作成する方法。 Python で最も単純なニューラル ネットワーク Python で人工知能を作成する方法
今週は、この職業を研究した GeekBrains の学生による、非常にやる気を起こさせる事例を読むことができます。そこで彼は、この職業に就いた目標の 1 つである、仕事の原理を学び、ゲーム ボットを自分で作成する方法を学びたいという願望について語っていました。
しかし、実際には、完璧なものを作りたいという願望があります。 人工知能それはともかく ゲームモデルまたは モバイルプログラム、私たちの多くがプログラマーになるきっかけを与えました。 問題は、トンの背後にあることです 教材そして顧客の厳しい現実を前に、その欲求そのものが自己啓発への単純な欲求に取って代わられました。 子供の頃の夢をまだ実現し始めていない人のために、本物の人工知能を作成するための短いガイドをここに示します。
ステージ 1. 失望
たとえ単純なボットの作成について話すときでも、私たちの目は輝きで満たされ、何ができるべきかについて何百ものアイデアが頭の中を駆け巡ります。 しかし、実際に実装してみると、実際の行動パターンを解明する鍵は数学であることがわかります。 はい、はい、人工知能は書くことよりもはるかに複雑です アプリケーションプログラム- ソフトウェア設計に関する知識だけでは十分ではありません。
数学は、さらなるプログラミングを構築するための科学的な出発点です。 この理論の知識と理解がなければ、人工知能は実際には一連の公式にすぎないため、人間の相互作用によりすべてのアイデアはすぐに壊れてしまいます。
ステージ 2. 受け入れ
学生文学によって傲慢さが少し打ち砕かれたら、練習を始めることができます。 まだ LISP などに急いで取り組む価値はありません。まず AI 設計の原則に慣れる必要があります。 Python は、素早い学習とさらなる開発の両方に最適です。Python は科学目的で最もよく使用される言語であり、作業を容易にする多くのライブラリが見つかります。
ステージ 3. 開発
それでは、AI の理論に直接移りましょう。 それらは大きく 3 つのカテゴリに分類できます。
- 弱い AI - 私たちが目にするボット コンピュータゲーム、または Siri のような単純なアシスタント。 彼らは高度に専門化されたタスクを実行するか、そのような重要でない複合体であり、相互作用の予測不可能性が彼らを困惑させます。
- 強力なAIとは、人間の脳に匹敵する知能を持つ機械のことです。 現在、このクラスを実際に代表する人はいませんが、ワトソンのようなコンピューターはこの目標の達成に非常に近づいています。
- 完璧な AI は未来であり、私たちの能力を超える機械の頭脳です。 スティーブン・ホーキング博士、イーロン・マスク、そして映画『ターミネーター』シリーズが警告しているのは、そのような発展の危険性である。
当然のことながら、最も単純なボットから始める必要があります。 これを行うには、3x3 フィールドを使用するときに古き良きゲーム「三目並べ」を思い出し、基本的なアクションのアルゴリズムを自分で理解してください。エラーのないアクションで勝利する確率、フィールド上で最も成功する場所などです。駒を置く、ゲームを引き分けにする必要性など。
数十のゲームをプレイして自分のアクションを分析すると、おそらくすべての重要な側面を特定し、それらをマシンコードに書き直すことができるでしょう。 そうでない場合は、考え続けてください。念のためにこのリンクがここにあります。
ちなみに、Python 言語をようやく始めた方は、この詳細なマニュアルを参照することで、かなり簡単なボットを作成できます。 C++ や Java などの他の言語の場合は、ステップバイステップの資料を見つけるのに問題はありません。 AI の作成の背後に超自然的なものは何もないと感じたら、ブラウザを安全に閉じて、個人的な実験を始めることができます。
ステージ 4. 興奮
物事が軌道に乗ったので、おそらくもっと本格的なものを作成したいと思うでしょう。 これには次のリソースが役立ちます。
名前からもわかるように、これらは次のことを可能にする API です。 追加費用本格的な AI のようなものを作成する時期が来ています。
ステージ 5. 作業
AI を作成する方法と何を使用するかについて明確なアイデアが得られたので、次はその知識を活用します。 新しいレベル。 まず、これには「機械学習」と呼ばれる学問を勉強する必要があります。 次に、選択したプログラミング言語の適切なライブラリを操作する方法を学ぶ必要があります。 ここで取り上げている Python は、Scikit-learn、NLTK、SciPy、PyBrain、Numpy です。 第三に、開発においては、 を回避する方法はありません。 そして最も重要なことは、AI について完全に理解した上で、AI に関する文献を読むことができるようになったということです。
- ゲームのための人工知能、イアン・ミリントン。
- ゲームプログラミングパターン、ロバート・ネイストーム、
- Prolog、Lisp、および Java の AI アルゴリズム、データ構造、およびイディオム、George Luger、William Stubfield。
- 計算論的認知神経科学、ランドール・オライリー、宗像裕子。
- 人工知能: 現代的なアプローチ、スチュアート・ラッセル、ピーター・ノーヴィグ。
そして、はい、このトピックに関するすべてまたはほぼすべての文献は外国語で提示されているため、専門的に AI を作成したい場合は、英語を向上させる必要があります。 技術レベル。 しかし、これはプログラミングのどの分野にも当てはまりますね。
今回はニューラルネットワークについて勉強することにしました。 私は2015年の夏から秋にかけて、この点に関する基礎的なスキルを習得することができました。 基本的なスキルとは、簡単なニューラル ネットワークを自分でゼロから作成できることを意味します。 私の GitHub リポジトリで例を見つけることができます。 この記事では、いくつかの説明を行い、学習に役立つリソースを共有します。
ステップ 1. ニューロンとフィードフォワード法
では、「ニューラルネットワーク」とは何でしょうか? これで待って、最初に 1 つのニューロンを処理しましょう。
ニューロンは関数に似ています。入力として複数の値を受け取り、1 つを返します。
下の円は人工ニューロンを表します。 5 を受け取り、1 を返します。入力は、ニューロンに接続されている 3 つのシナプスの合計です (左側の 3 つの矢印)。
画像の左側には 2 つの入力値が表示されます ( 緑) とオフセット (茶色で強調表示)。
入力データは、2 つの異なるプロパティの数値表現にすることができます。 たとえば、スパム フィルターを作成する場合、大文字で書かれた複数の単語の存在や、「Viagra」という単語の存在を意味する可能性があります。
入力値には、いわゆる「重み」、7 と 3 (青で強調表示) が乗算されます。
次に、結果の値をオフセットと加算して数値を取得します。この場合は 5 (赤で強調表示) です。 これは人工ニューロンの入力です。

次に、ニューロンは何らかの計算を実行し、出力値を生成します。 1 を獲得しました。 ポイント 5 のシグモイドの丸められた値は 1 です (この関数については後で詳しく説明します)。
これがスパム フィルターの場合、出力 1 という事実は、テキストがニューロンによってスパムとしてマークされたことを意味します。

Wikipedia からのニューラル ネットワークの図。
これらのニューロンを結合すると、直接伝播するニューラル ネットワークが得られます。左の図のように、プロセスはシナプスで接続されたニューロンを介して入力から出力まで進みます。
ステップ 2. シグモイド
Welch Labs のレッスンを視聴した後は、ニューラル ネットワークに関する Coursera の機械学習コースの第 4 週をチェックして、ニューラル ネットワークがどのように機能するかを理解することをお勧めします。 このコースは数学を非常に深く掘り下げており、Octave に基づいていますが、私は Python の方が好きです。 このため、演習はスキップし、必要な知識はすべてビデオから得ました。

シグモイドは、(横軸上の) 値を 0 から 1 の範囲にマッピングするだけです。
私の最優先事項は、ニューラル ネットワークの多くの側面で解明されているシグモイドを研究することでした。 上記コースの3週目である程度は分かっていたので、そこから動画を見ました。
しかし、ビデオだけでは遠くまで到達することはできません。 完全に理解するために、自分でコーディングすることにしました。 そこで私は、ロジスティック回帰アルゴリズム (シグモイドを使用する) の実装を書き始めました。
丸一日かかりましたが、結果は満足のいくものではありませんでした。 でも、すべてがどのように機能するかを理解したので、それは問題ではありません。 コードが見えます。
これには特別な知識が必要なので、自分で行う必要はありません。重要なのは、シグモイドがどのように機能するかを理解することです。
ステップ 3. バックプロパゲーション法
ニューラル ネットワークが入力から出力までどのように動作するかを理解することは、それほど難しいことではありません。 ニューラル ネットワークがデータセットからどのように学習するかを理解することははるかに困難です。 私が使用した原理は次のように呼ばれます
私たちは今、ニューラル ネットワークの本格的なブームを経験しています。 これらは、認識、位置特定、画像処理に使用されます。 ニューラル ネットワークは、人間にはできない多くのことをすでに実行できます。 私たち自身がこの問題に関与する必要があります。 入力画像内の数字を認識する中性子ネットワークを考えてみましょう。 それは非常にシンプルです: 1 つのレイヤーとアクティベーション関数だけです。 これにより、完全にすべてのテスト画像を認識できるわけではありませんが、大部分は処理できます。 データとして、数値認識の世界でよく知られている MNIST データ コレクションを使用します。
Python でこれを操作するには、ライブラリ python-mnist があります。 インストールするには:
Pip インストール python-mnist
これでデータをロードできるようになりました
mnist からインポート MNIST mndata = MNIST("/path_to_mnist_data_folder/") tr_images, tr_labels = mndata.load_training() test_images, test_labels = mndata.load_testing()
データを含むアーカイブを自分でダウンロードし、それらが含まれるディレクトリへのパスをプログラムに指定する必要があります。 これで、tr_images 変数と test_images 変数に、それぞれネットワーク トレーニングとテスト用のイメージが含まれるようになりました。 そして、変数 tr_labels と test_labels は、正しい分類 (つまり、画像からの番号) を持つラベルです。 すべての画像のサイズは 28x28 です。 サイズを変数に設定してみましょう。
Img_shape = (28, 28)
すべてのデータを numpy 配列に変換し、正規化してみましょう (-1 から 1 までのサイズにサイズ変更します)。 これにより、計算の精度が向上します。
range(0, len(test_images)) の i に対して numpy を np としてインポートします: test_images[i] = np.array(test_images[i]) / 255 for i in range(0, len(tr_images)): tr_images[i] = np.array(tr_images[i]) / 255
画像を 2 次元配列として表すのが通例ですが、ここでは計算が簡単な 1 次元配列を使用することに注意してください。 ここで「ニューラルネットワークとは何か」を理解する必要があります。 そして、これは単なる方程式です 多数の係数 28*28=784 要素の入力配列と、各桁を決定するための別の 784 の重みがあります。 ニューラル ネットワークの動作中、入力値に重みを乗算する必要があります。 結果のデータを追加し、オフセットを追加します。 得られた結果はアクティベーション関数に供給されます。 私たちの場合、それは Relu になります。 この関数は、すべての負の引数に対してゼロに等しく、すべての正の引数に対してゼロに等しくなります。

他にもたくさんのアクティベーション関数があります。 しかし、これは最も単純なニューラル ネットワークです。 numpyを使用してこの関数を定義しましょう
Def relu(x): np.maximum(x, 0) を返す
ここで、画像内の画像を計算するには、10 セットの係数の結果を計算する必要があります。
Def nn_calculate(img): resp = list(range(0, 10)) for i in range(0,10): r = w[:, i] * img r = relu(np.sum(r) + b[ i]) resp[i] = r return np.argmax(resp)
セットごとに出力結果を取得します。 最も高い結果が得られる出力は、おそらくこの数値です。

で この場合 7. 以上です! しかし、違います... 結局のところ、これらの同じ係数をどこかで取得する必要があります。 ニューラルネットワークをトレーニングする必要があります。 これを行うには、バックプロパゲーション法が使用されます。 その本質は、ネットワーク出力を計算し、それらを正しい出力と比較し、正しい結果を得るために必要な数値を係数から減算することです。 これらの値を計算するには、活性化関数の導関数が必要であることに注意してください。 この場合、すべての負の数は 0 に等しく、すべての正の数は 1 に等しくなります。 係数をランダムに決定しましょう。
W = (2*np.random.rand(10, 784) - 1) / 10 b = (2*np.random.rand(10) - 1) / 10 for n in range(len(tr_images)): img = tr_images[n] cls = tr_labels[n] #forward propagation resp = np.zeros(10, dtype=np.float32) for i in range(0,10): r = w[i] * img r = relu( np.sum(r) + b[i]) resp[i] = r resp_cls = np.argmax(resp) resp = np.zeros(10, dtype=np.float32) resp = 1.0 #back propagation true_resp = np。 zeros(10, dtype=np.float32) true_resp = 1.0 error = resp - true_resp delta = error * ((resp >= 0) * np.ones(10)) for i in range(0,10): w[i ] -= np.dot(img, デルタ[i]) b[i] -= デルタ[i]
トレーニングが進むにつれて、係数は次のような数字のように見え始めます。
作業の精度を確認してみましょう。
Def nn_calculate(img): resp = list(range(0, 10)) for i in range(0,10): r = w[i] * img r = np.maximum(np.sum(r) + b[ i], 0) #relu resp[i] = r return np.argmax(resp) total = len(test_images) 有効 = 0 無効 = for i in range(0, total): img = test_images[i] 予測 = nn_calculate (img) true = test_labels[i] 予測 == true の場合: 有効 = 有効 + 1 それ以外: 無効.append(("image":img, "予測":予測, "true":true)) print("精度()".format(有効/合計))
88%を獲得しました。 それほどクールではありませんが、非常に興味深いです!
ニューラル ネットワークは主に次のように作成およびトレーニングされます。 Python言語。 したがって、プログラムの作成方法の基本を理解することが非常に重要です。 この記事では、この言語の基本概念である変数、関数、クラス、モジュールについて簡単かつ明確に説明します。
この資料は、プログラミング言語に詳しくない人を対象としています。
まず、Python をインストールする必要があります。 次に、Python でプログラムを作成するための便利な環境をインストールする必要があります。 ポータルはこれら 2 つのステップ専用です。
すべてがインストールされ、設定されていれば、開始できます。
変数
変数- あらゆるプログラミング言語 (プログラミング言語に限らず) における重要な概念。 変数をラベルの付いたボックスとして考える最も簡単な方法です。 このボックスには、私たちにとって価値のあるもの (数値、行列、オブジェクトなど) が含まれています。
たとえば、値 10 を格納する変数 x を作成したいとします。Python では、この変数を作成するコードは次のようになります。

左側に私たちは 私たちは発表します x という名前の変数。 これは箱に名札を付けることに相当します。 次に等号と数字の 10 が続きます。ここでは等号が珍しい役割を果たします。 「x が 10 に等しい」という意味ではありません。 この場合の等価性では、ボックスに数値 10 が入ります。 より正確に言うと、私たちは、 割り当てる変数 x は数値 10 です。
さて、以下のコードでは、この変数にアクセスし、それを使用してさまざまなアクションを実行することもできます。
この変数の値を画面に表示するだけです。
X=10 印刷(x)
print(x) は関数呼び出しを表します。 それらについてはさらに検討していきます。 ここで重要なことは、この関数が括弧の間にある内容をコンソールに出力するということです。 括弧の間には x があります。 以前は、x に値 10 を割り当てました。上記のプログラムを実行すると、これがコンソールに 10 と表示されます。
数値を格納する変数を使用して、加算、減算、乗算、除算、累乗などのさまざまな単純な演算を実行できます。
X = 2 y = 3 # 加算 z = x + y print(z) # 5 # 差 z = x - y print(z) # -1 # 積 z = x * y print(z) # 6 # 除算 z = x / y print(z) # 0.66666... # べき乗 z = x ** y print(z) # 8
上記のコードでは、まず 2 と 3 を含む 2 つの変数を作成します。次に、x と y の演算結果を格納する変数 z を作成し、その結果をコンソールに出力します。 この例は、プログラムの実行中に変数の値が変更される可能性があることを明確に示しています。 したがって、変数 z はその値を 5 回も変更します。
機能
場合によっては、同じ操作を何度も実行する必要があることがあります。 たとえば、私たちのプロジェクトでは、多くの場合、5 行のテキストを表示する必要があります。
「これはとても重要な文章です!」
「この文字は読めません」
「トップラインのミスは意図的に行われた」
「こんにちは、さようなら」
"終わり"
コードは次のようになります。
X = 10 y = x + 8 - 2 print("これは非常に重要なテキストです!") print("このテキストは読めません") print("先頭行の間違いは意図的に行われたものです") print("こんにちは、さようなら") print ("終わり") z = x + y print("これは非常に重要なテキストです!") print("このテキストは読めません") print("上の行が間違っていますわざと」) print(「こんにちは、さようなら」) print (「終わり」) test = z print(「これは非常に重要なテキストです!」) print("このテキストは読めません") print("一番上の行は意図的に作成したものです") print("こんにちは、さようなら") print(" 終了")
それはすべて非常に冗長で不便に見えます。 また、2行目に誤りがありました。 固定は可能ですが、一度に3箇所を固定する必要があります。 これらの 5 行がプロジェクトで 1000 回呼び出されたらどうなるでしょうか? そして、すべてが異なる場所とファイルにあるのでしょうか?
特に同じコマンドを頻繁に実行する必要がある場合は、プログラミング言語で関数を作成できます。
関数- 名前で呼び出すことができる別のコード ブロック。
関数は def キーワードを使用して定義されます。 これに関数の名前が続き、その後に括弧とコロンが続きます。 次に、関数が呼び出されたときに実行されるアクションをインデントしてリストする必要があります。
Def print_5_lines(): print("これは非常に重要なテキストです!") print("このテキストは読めません") print("先頭行の間違いは意図的に行われたものです") print("こんにちは、さようなら") print("終わり")
これで、print_5_lines() 関数が定義されました。 ここで、プロジェクトに再度 5 行を挿入する必要がある場合は、関数を呼び出すだけです。 すべてのアクションを自動的に実行します。
# 関数を定義します def print_5_lines(): print("これは非常に重要なテキストです!") print("このテキストは読み取れません") print("先頭行のエラーは意図的です") print("こんにちは、さようなら") print(" End") # プロジェクトコード x = 10 y = x + 8 - 2 print_5_lines() z = x + y print_5_lines() test = z print_5_lines()
便利ですね。 コードの読みやすさを大幅に改善しました。 また、一部のアクションを変更したい場合は、関数自体を修正するだけで済むため、関数も便利です。 この変更は、関数が呼び出されるすべての場所で機能します。 つまり、関数本体の出力テキストの 2 行目のエラー (「no」 > 「no」) を修正できます。 プロジェクト内のすべての場所で正しいオプションが自動的に呼び出されます。

パラメータ付き関数
確かに、いくつかの操作を繰り返すだけでは便利です。 しかし、それだけではありません。 場合によっては、関数に変数を渡したいことがあります。 こうすることで、関数はデータを受け取り、コマンドの実行中にそれを使用できます。
関数に渡す変数は次のように呼ばれます。 引数.
書いてみましょう 単純な機能、与えられた 2 つの数値を加算し、結果を返します。
Def sum(a, b): result = a + b 結果を返します
最初の行は通常の関数とほぼ同じです。 しかし、括弧の間には 2 つの変数があります。 これ パラメータ機能。 この関数には 2 つのパラメーターがあります (つまり、2 つの変数を取ります)。
パラメーターは、通常の変数と同様に関数内で使用できます。 2 行目では、パラメータ a と b の合計に等しい変数 result を作成します。 3 行目では、結果変数の値を返します。
ここで、さらにコードを記述すると、次のようになります。
New = sum(2, 3) print(new)
sum 関数を呼び出し、2 つの引数と 3 を順番に渡します。2 は変数 a の値になり、3 は変数 b の値になります。 関数は値 (2 と 3 の合計) を返し、それを使用して新しい変数 new を作成します。
覚えて。 上記のコードでは、数値 2 と 3 は sum 関数の引数です。 また、sum 関数自体では、変数 a と b がパラメーターです。 言い換えれば、関数が呼び出されたときに関数に渡す変数は引数と呼ばれます。 ただし、関数内では、渡されるこれらの変数はパラメーターと呼ばれます。 実際、これらは同じものを表す 2 つの名前ですが、混同しないでください。
別の例を見てみましょう。 1 つの数値を受け取り、それを 2 乗する関数 square(a) を作成しましょう。
Def square(a): a * a を返す
私たちの関数はたった 1 行で構成されています。 パラメーター a と a を乗算した結果をすぐに返します。
関数を使用してコンソールにデータを出力することもすでにおわかりかと思います。 この関数は print() と呼ばれ、渡された引数 (数値、文字列、変数) をコンソールに出力します。
配列
変数が何か (数値である必要はない) を格納する箱と考えることができる場合、配列は本棚と考えることができます。 それらには一度に複数の変数が含まれます。 次に、3 つの数値と 1 つの文字列の配列の例を示します。
配列 =
以下は、変数に数値ではなく他のオブジェクトが含まれている場合の例です。 この場合、変数には配列が含まれています。 配列の各要素には番号が付けられます。 配列の要素を表示してみましょう。
配列 = print(配列)
コンソールには 89 という数字が表示されます。しかし、なぜ 1 ではなく 89 なのでしょうか? 重要なのは、Python では、他の多くのプログラミング言語と同様に、配列の番号付けは 0 から始まるということです。 2番最初の要素ではなく、配列の要素です。 最初のものを呼び出すには、 array を記述する必要がありました。
配列サイズ
場合によっては、配列内の要素の数を取得すると非常に便利です。 これには len() 関数を使用できます。 要素の数をカウントし、その数を返します。
配列 = print(len(配列))
コンソールには数字の 4 が表示されます。
条件とサイクル
デフォルトでは、どのプログラムでも、すべてのコマンドが上から下まで連続して実行されます。 しかし、ある条件を確認し、それが真か否かに応じて異なるアクションを実行する必要がある状況もあります。
さらに、ほとんど同じ一連のコマンドを何度も繰り返す必要があることがよくあります。
最初の状況では条件が役立ち、2 つ目の状況ではサイクルが役立ちます。
条項
テスト対象のステートメントが true か false かに応じて、2 つの異なるアクション セットを実行するには条件が必要です。

Python では、if: ... else: ... 構造を使用して条件を記述することができます。 変数 x = 10 を考えてみましょう。 x が 10 未満の場合、x を 2 で除算します。x が 10 以上の場合、x と数値 100 の合計に等しい別の変数 new を作成します。これは、コードは次のようになります。
X = 10 if(x< 10): x = x / 2 print(x) else: new = x + 100 print(new)
変数 x を作成した後、条件の記述を開始します。
すべてはキーワード if (英語から「if」と翻訳) で始まります。 括弧内はチェック対象の式を示します。 この場合、変数 x が本当に 10 未満であるかどうかを確認します。本当に 10 未満である場合は、それを 2 で割って、結果をコンソールに出力します。
それから来ます キーワード else の後に、 if の後の括弧内の式が false の場合に実行されるアクションのブロックが始まります。
10 以上の場合は、x + 100 に等しい新しい変数 new を作成し、それをコンソールに出力します。
サイクル
ループはアクションを何度も繰り返すために必要です。 最初の 10 個の正方形の表を表示したいとします。 自然数。 このようにして行うことができます。
Print("正方形 1 は " + str(1**2)) print("正方形 2 は " + str(2**2)) print("正方形 3 は " + str(3**2)) print( "正方形 4 は " + str(4**2)) print("正方形 5 は " + str(5**2)) print("正方形 6 は " + str(6**2)) print("正方形7 は " + str(7**2)) print("8 の 2 乗は " + str(8**2)) print("9 の 2 乗は " + str(9**2)) print("Square 10 のうち は " + str(10**2))
行を追加しても驚かないでください。 Python の「行の始まり」+「終わり」は、単に文字列を連結することを意味します:「行の始まり」。 上記と同様に、「x の 2 乗は に等しい」という文字列と、その数値の 2 乗を関数 str(x**2) で変換した結果を加算します。
上記のコードは非常に冗長に見えます。 最初の 100 個の数字の四角形を出力する必要がある場合はどうすればよいでしょうか? 私たちは撤退するのに苦しんでいます...
このような場合にこそサイクルが存在します。 Python には while と for の 2 種類のループがあります。 一つ一つ対処していきましょう。
while ループは、条件が true である限り、必要なコマンドを繰り返します。
X = 1 のとき、x<= 100: print("Квадрат числа " + str(x) + " равен " + str(x**2)) x = x + 1
まず変数を作成し、それに数値 1 を割り当てます。次に while ループを作成し、x が 100 より小さい (または等しい) かどうかを確認します。 それより小さい (または等しい) 場合は、2 つのアクションを実行します。
- 平方 x を出力します
- xを1増やす
2 番目のコマンドの後、プログラムはその状態に戻ります。 条件が再び true の場合は、これら 2 つのアクションを再度実行します。 x が 101 に等しくなるまで同様です。その後、条件は false を返し、ループは実行されなくなります。
for ループは配列を反復処理するように設計されています。 最初の 100 個の自然数の 2 乗を使用して、for ループを使用して同じ例を書いてみましょう。
range(1,101) の x の場合: print("数値の 2 乗 " + str(x) + " は " + str(x**2))
最初の行を見てみましょう。 for キーワードを使用してループを作成します。 次に、1 ~ 100 の範囲内のすべての x に対して特定のアクションを繰り返すことを指定します。関数 range(1,101) は、1 から始まり 100 で終わる 100 個の数値の配列を作成します。
for ループを使用して配列を反復処理する別の例を次に示します。
i の場合: print(i * 2)
上記のコードは、2、20、200、2000 の 4 つの数値を出力します。ここでは、配列の各要素を取得して一連のアクションを実行する方法が明確にわかります。 次に、次の要素を取得し、同じ一連のアクションを繰り返します。 配列内の要素がなくなるまで続きます。
クラスとオブジェクト
実生活では、私たちは変数や関数を操作するのではなく、オブジェクトを操作します。 ペン、車、人、猫、犬、飛行機 - オブジェクト。 では、猫を詳しく見てみましょう。
いくつかのパラメーターがあります。 これらには、毛皮の色、目の色、および彼女のニックネームが含まれます。 しかし、それだけではありません。 パラメータに加えて、猫はゴロゴロと喉を鳴らす、シューシューと鳴る、引っ掻くなどのさまざまなアクションを実行できます。
私たちは猫全般を概略的に説明しました。 似ている プロパティとアクションの説明 Python では、あるオブジェクト (猫など) をクラスと呼びます。 クラスは、オブジェクトを記述する変数と関数のセットにすぎません。
クラスとオブジェクトの違いを理解することが重要です。 クラス - スキーム、オブジェクトについて説明します。 対象は彼女です 素材の具現化。 猫のクラスは、その特性と行動の説明です。 猫のオブジェは本物の猫そのものです。 さまざまな本物の猫、つまり多くの猫のオブジェクトが存在する可能性があります。 ただし、猫のクラスは 1 つだけです。 良いデモンストレーションは以下の図です。

クラス
クラス (猫のスキーマ) を作成するには、キーワード class を記述し、このクラスの名前を指定する必要があります。
クラス猫:
次に、このクラスのアクション (cat アクション) をリストする必要があります。 ご想像のとおり、アクションはクラス内で定義された関数です。 クラス内のこのような関数は通常、メソッドと呼ばれます。
方法- クラス内で定義された関数。
喉を鳴らす、シューシューと鳴く、引っ掻くなど、猫のやり方を口頭で説明しました。 では、Python でやってみましょう。
# Cat クラス class Cat: # Purr def purr(self): print("Purrr!") # Hiss def hiss(self): print("Shh!") # Scratch def scrabble(self): print("Scratch-scratch !」)
それはとても簡単です! 3 つの通常の関数を取得して定義しましたが、それはクラス内のみでした。
理解できない self パラメータに対処するために、cat にメソッドをもう 1 つ追加しましょう。 このメソッドは、すでに作成されている 3 つのメソッドをすべて一度に呼び出します。
# Cat クラス class Cat: # Purr def purr(self): print("Purrr!") # Hiss def hiss(self): print("Shh!") # Scratch def scrabble(self): print("Scratch-scratch !") # すべて一緒に def all_in_one(self): self.purr() self.hiss() self.scrabble()
ご覧のとおり、あらゆるメソッドに必要な self パラメーターを使用すると、クラス自体のメソッドと変数にアクセスできるようになります。 この議論がなければ、そのようなアクションを実行することはできません。
次に、猫のプロパティ (毛皮の色、目の色、ニックネーム) を設定しましょう。 これを行うにはどうすればよいでしょうか? どのクラスでも __init__() 関数を定義できます。 この関数は、クラスの実際のオブジェクトを作成するときに常に呼び出されます。
上で強調表示した __init__() メソッドでは、cat の変数を設定します。 どうやってこれを行うのでしょうか? まず、毛色、目の色、ニックネームを決定する 3 つの引数をこのメソッドに渡します。 次に、self パラメータを使用して、オブジェクトの作成時に猫に上記の 3 つの属性を即座に設定します。
この行はどういう意味ですか?
Self.wool_color = ウールの色
左側では、wool_color という猫の属性を作成し、__init__() 関数に渡した Wool_color パラメータに含まれる値をこの属性に割り当てます。 ご覧のとおり、上記の行は通常の変数作成と何ら変わりません。 接頭辞 self のみが、この変数が Cat クラスに属していることを示します。
属性- クラスに属する変数。
そこで、既製の猫クラスを作成しました。 彼のコードは次のとおりです。
# Cat クラス class Cat: # 「Cat」オブジェクトの作成時に実行されるアクション def __init__(self, Wool_color, names_color, name): self.wool_color = Wool_color self.eyes_color = names_color self.name = name # Purr def purr( self): print("Purrr!") # ヒス def hiss(self): print("Shh!") # スクラッチ def scrabble(self): print("Scratch-scratch!") # 全部まとめて def all_in_one(self) : self.purr() self.hiss() self.scrabble()
オブジェクト
猫の図を作成しました。 次に、このスキームを使用して実際の猫オブジェクトを作成しましょう。
My_cat = 猫("黒", "緑", "ゾーシャ")
上の行では、変数 my_cat を作成し、それに Cat クラスのオブジェクトを割り当てます。 これはすべて、何らかの関数 Cat(...) の呼び出しのように見えます。 実際、これは真実です。 このエントリでは、Cat クラスの __init__() メソッドを呼び出します。 私たちのクラスの __init__() 関数は 4 つの引数を取ります。指定する必要のない self クラス オブジェクト自体と、さらに 3 つの異なる引数で、これらは cat の属性になります。
したがって、上の行を使用して、実際の猫のオブジェクトを作成しました。 私たちの猫には、黒い毛皮、緑色の目、そしてゾシャというニックネームが備わっています。 これらの属性をコンソールに出力してみましょう。
プリント(my_cat.wool_color) プリント(my_cat.eyes_color) プリント(my_cat.name)
つまり、オブジェクトの名前を書き、ドットを入力して目的の属性の名前を示すことによって、オブジェクトの属性にアクセスできます。
猫の属性は変更可能です。 たとえば、猫の名前を変更してみましょう。
My_cat.name = "ニューシャ"
ここで、コンソールに猫の名前を再度表示すると、Zosia ではなく Nyusha が表示されます。
私たちの猫のクラスでは特定のアクションを実行できることを思い出してください。 私たちがゾーシャ/ニューシャを撫でると、彼女は喉を鳴らし始めます。
My_cat.purr()
このコマンドを実行すると、「Purrr!」というテキストがコンソールに出力されます。 ご覧のとおり、オブジェクトのメソッドへのアクセスは、その属性へのアクセスと同じくらい簡単です。
モジュール
.py 拡張子を持つファイルはすべてモジュールです。 あなたがこの記事に取り組んでいるものも。 なぜそれらが必要なのでしょうか? 便宜上。 便利な関数やクラスを含むファイルを作成する人はたくさんいます。 他のプログラマは、これらのサードパーティ モジュールに接続し、モジュール内で定義されているすべての関数とクラスを使用できるため、作業が簡素化されます。
たとえば、行列を操作するために独自の関数を作成して時間を無駄にする必要はありません。 numpy モジュールを接続し、その関数とクラスを使用するだけで十分です。
現時点では、他の Python プログラマーが 110,000 を超えるさまざまなモジュールを作成しています。 前述の numpy モジュールを使用すると、行列や多次元配列をすばやく便利に操作できるようになります。 math モジュールは、サイン、コサイン、度数からラジアンへの変換など、数値を扱うための多くのメソッドを提供します。
モジュールのインストール
Python は、標準のモジュール セットとともにインストールされます。 このセットには、数学の操作、Web リクエスト、ファイルの読み取りと書き込み、その他の必要なアクションの実行を可能にする非常に多数のモジュールが含まれています。
標準セットに含まれていないモジュールを使用する場合は、インストールする必要があります。 モジュールをインストールするには、コマンド ラインを開き (Win + R を押し、表示されるフィールドに「cmd」と入力します)、そこにコマンドを入力します。
Pip インストール [モジュール名]
モジュールのインストールプロセスが開始されます。 完了すると、インストールされたモジュールをプログラムで安全に使用できるようになります。
モジュールの接続と使用
サードパーティ製モジュールの接続は非常に簡単です。 1 行の短いコードを記述するだけで済みます。
[モジュール名] をインポートします
たとえば、数学関数を操作できるようにするモジュールをインポートするには、次のように記述する必要があります。
数学をインポートする
モジュール関数にアクセスするにはどうすればよいですか? モジュールの名前を書いてから、ドットを入れて関数/クラスの名前を書く必要があります。 たとえば、階乗 10 は次のように求められます。
数学.階乗(10)
つまり、数学モジュール内で定義されている階乗関数 (a) に注目しました。 これは、時間を無駄にして数値の階乗を計算する関数を手動で作成する必要がないので便利です。 モジュールを接続すると、必要なアクションをすぐに実行できます。
ジェームス・ロイ、ジョージア工科大学。 Python で独自のニューラル ネットワークを作成するための初心者ガイド。
モチベーション:ディープラーニングを研究した個人的な経験に基づいて、たとえば のような複雑なトレーニング ライブラリを使用せずに、ニューラル ネットワークを最初から作成することにしました。 データ サイエンティストの初心者にとって、ニューラル ネットワークの内部構造を理解することが重要であると私は考えています。
この記事には私が学んだことが含まれており、あなたにも役立つことを願っています。 このトピックに関するその他の役立つ記事:
ニューラルネットワークとは何ですか?
ニューラル ネットワークに関する記事のほとんどは、ニューラル ネットワークを説明する際に脳との類似点を描いています。 あまり詳しく説明することなく、ニューラル ネットワークを特定の入力を目的の出力にマッピングする数学関数として説明する方が簡単です。
ニューラル ネットワークは次のコンポーネントで構成されます。
- 入力層、x
- 任意の量 隠しレイヤー
- 出力層、ŷ
- キット 天秤そして 変位各層の間 W そして b
- 選択 活性化関数隠れ層ごとに σ ; この作業では、シグモイド活性化関数を使用します。
以下の図は、2 層ニューラル ネットワークのアーキテクチャを示しています (ニューラル ネットワークの層数を数えるとき、通常、入力層は除外されることに注意してください)。
Python でニューラル ネットワーク クラスを作成するのは簡単です。
ニューラルネットワークトレーニング
出口 ŷ 単純な 2 層ニューラル ネットワーク:
上式では、出力 ŷ に影響を与える変数は重み W とバイアス b だけです。
当然のことながら、重みとバイアスの正しい値によって予測の精度が決まります。 入力データから重みとバイアスを微調整するプロセスは、ニューラル ネットワーク トレーニングとして知られています。
学習プロセスの各反復は次のステップで構成されます。
- 順伝播と呼ばれる、予測出力 ŷ の計算
- バックプロパゲーションと呼ばれる重みとバイアスの更新
以下の連続グラフはプロセスを示しています。
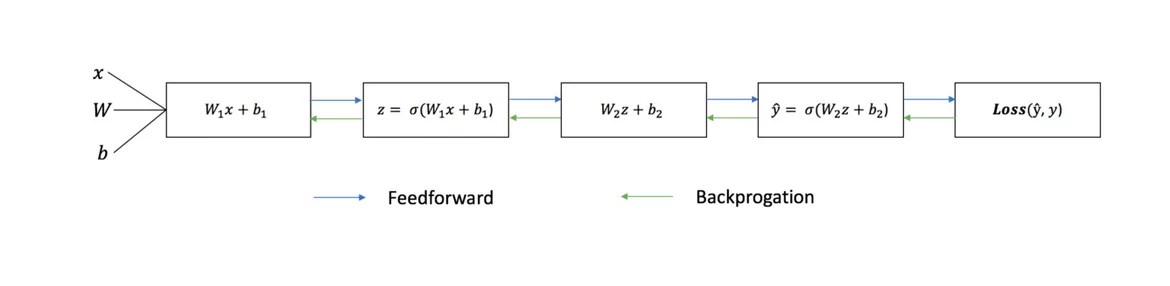
直接配布
上のグラフで見たように、順伝播は単なる単純な計算であり、基本的な 2 層ニューラル ネットワークの場合、ニューラル ネットワークの出力は次のように与えられます。
これを行うために、Python コードに順伝播関数を追加しましょう。 簡単にするために、オフセットが 0 であると仮定していることに注意してください。
ただし、予測の「良さ」、つまり予測がどの程度離れているかを評価する方法が必要です)。 損失関数これを実行できるようにするだけです。
損失関数
利用可能な損失関数は多数あり、問題の性質によって損失関数の選択が決まります。 この作業で使用するのは、 二乗誤差の合計損失関数として。

二乗誤差の合計は、各予測値と実際の値の差の平均です。
学習の目標は、損失関数を最小化する重みとバイアスのセットを見つけることです。
バックプロパゲーション
予測の誤差 (損失) を測定したので、次は方法を見つける必要があります。 エラーを伝播して戻すそして重みとバイアスを更新します。
重みとバイアスを調整するための適切な量を知るには、重みとバイアスに関する損失関数の導関数を知る必要があります。
分析から次のことを思い出してください。 関数の導関数は関数の傾きです。

導関数がある場合は、重みとバイアスを増減するだけで更新できます (上の図を参照)。 それは呼ばれます 勾配降下法.
ただし、損失関数の方程式には重みとバイアスが含まれていないため、重みとバイアスに関する損失関数の導関数を直接計算することはできません。 したがって、計算を支援する連鎖規則が必要です。
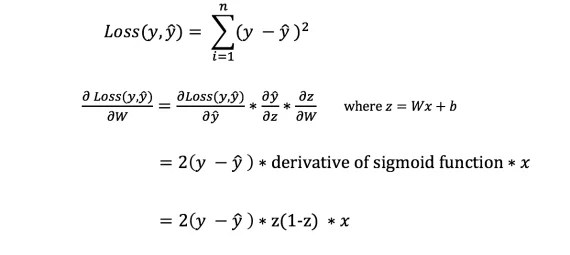
ふう! これは面倒でしたが、これにより、必要なもの、つまり重みに関する損失関数の導関数 (傾き) を取得することができました。 これで、それに応じて重みを調整できるようになりました。
バックプロパゲーション関数を Python コードに追加しましょう。
ニューラルネットワークの動作確認
順伝播と逆伝播を実行するための完全な Python コードが完成したので、例を使用してニューラル ネットワークを詳しく見て、それがどのように機能するかを見てみましょう。
 理想的なスケールのセット
理想的なスケールのセット 私たちのニューラル ネットワークは、この関数を表すための理想的な重みのセットを学習する必要があります。
ニューラル ネットワークを 1500 回反復してトレーニングし、何が起こるかを見てみましょう。 以下の反復損失プロットを見ると、損失が最小値まで単調減少していることが明確にわかります。 これは、前に説明した勾配降下法アルゴリズムと一致しています。

1500 回の反復後のニューラル ネットワークからの最終的な予測 (出力) を見てみましょう。

やった!私たちの順伝播アルゴリズムと逆伝播アルゴリズムは、ニューラル ネットワークが正常に動作し、予測が真の値に収束することを示しました。
予測値と実際の値には若干の差異があることに注意してください。 これにより、過剰適合が防止され、ニューラル ネットワークが目に見えないデータに対してより適切に一般化できるようになるため、これは望ましいことです。
最終的な考え
独自のニューラル ネットワークをゼロから作成する過程で多くのことを学びました。 TensorFlow や Keras などのディープ ラーニング ライブラリを使用すると、ニューラル ネットワークの内部動作を完全に理解していなくてもディープ ネットワークを構築できますが、データ サイエンティストを志す人がニューラル ネットワークをより深く理解するには役立つと思います。
私はこの仕事に多くの個人的な時間を費やしてきました。お役に立てば幸いです。
-
 2015 年 4 月 17 日スクリーンショットは Windows のどこに保存されますか?
2015 年 4 月 17 日スクリーンショットは Windows のどこに保存されますか? -
 2015 年 4 月 17 日Microsoft Internet Explorer での Xmarks アドオンのセットアップ
2015 年 4 月 17 日Microsoft Internet Explorer での Xmarks アドオンのセットアップ -
 2015 年 4 月 17 日売り手がAliexpressでの紛争を終了するように要求した場合はどうすればよいですか?
2015 年 4 月 17 日売り手がAliexpressでの紛争を終了するように要求した場合はどうすればよいですか? -
 2015 年 4 月 17 日オンラインで電話番号に発信した相手を調べる
2015 年 4 月 17 日オンラインで電話番号に発信した相手を調べる





