MS SQL Server データベースの定期的なバックアップを設定します。 SQL Express Edition サーバーでの SQL データベースの自動バックアップの作成 SQL バックアップの作成
sqlcmd -S DECLSERVER\SQLGTD -E -Q "declare @s varchar(255) set @s='E:\backup\GTD_' + Convert(varchar(1), datepart(dw, getdate())) + '。 bak' データベース GTD をディスクにバックアップ = @s (init、noformat、skip、nounload 付き)
sqlcmd Transact-SQL ステートメント、システム プロシージャ、スクリプト ファイルを次から入力できます。 コマンドライン SQLCMD モードのクエリ エディターに、
- -S - サーバー名を指定します。 サーバー[\インスタンス名];
- DECLServer\SQLGTD - データベースが実行されるサーバー名/インスタンス名。
- -E - ユーザー名とパスワードの代わりに信頼された接続を使用して SQL サーバーに接続します。
- -Q "コマンドラインクエリ" - プログラムの開始時 sqlcmdリクエストを実行しますが、実行完了時にプログラムを終了しません。 複数のクエリをセミコロンで区切って実行できます。 上に示したように、クエリを引用符で囲みます。
- 宣言する - 変数 s を宣言します。変数名は常に @ で始まるため、 @s。 私たちの場合 @s- これはバックアップを保存するためのフォルダー (ディスク) です。
- varchar(n) - 変数の型を設定します @s長い文字列 n を持つ文字列として、この例では 255 文字です。
- セット - 変数の値を設定します @s、この例では、これはドライブ E のバックアップ フォルダーです ( E:\バックアップ\)、バックアップ ファイルの名前を指定します。ここで、一連の関数は Convert(varchar(1), datepart(dw, getdate()))に戻ります テキスト形式現在の曜日 (月曜日 - 1 、 火曜日 - 2 、など)拡張子が追加されます バク。 出力は次の名前のファイルになります。 GTD_曜日番号.bak;
- バックアップ - バックアップを作成します。
- データベース - データベース全体のバックアップの作成を示します。
- GTD - この例では、SQL サーバー上のデータベースの名前。
- ディスクへ - バックアップストレージデバイス、ファイルのタイプを示します。 ハードドライブ、変数が指定されています @s、作成されるファイルのパスと名前が割り当てられます。
- init、noformat、skip、nounload あり - は、ヘッダーを再定義してデータを円形に書き換える必要があることを示します。これにより、曜日ごとに 7 つのバックアップ ファイルを円形に書き換えることができます。
必要に応じて、圧縮などの他の関数を使用できます。「Transact-SQL クエリと関数のヘルプ」を参照してください。
ステップ 2. テキスト ファイルの拡張子を .cmd に変更します。
その結果、ファイルを取得します バックアップGTD.cmd。 実行が作成されました バッチファイル MS SQL データベースがインストールされているマシンから必要です。
ステップ 3. このプロセスを自動化する
MS を例としてこのステップを考えてみましょう Windowsサーバー 2008: サーバー マネージャー -> 構成 -> ジョブ スケジューラ -> ジョブ スケジューラ ライブラリ。
データベース管理者は、バックアップを行う者とバックアップを行う者に分かれます。
導入
この記事では、MS ツールを使用した最も一般的な IB 1C バックアップについて説明します。 SQLサーバー 2008 R2 では、他の方法ではなくこの方法で実行する必要がある理由を説明し、いくつかの誤解を払拭します。 この記事には MS SQL ドキュメントへの参照が多く含まれています。この記事はメカニズムの概要を説明するものです。 バックアップ包括的なガイドよりも。 しかし、初めてこのタスクに直面する人にとっては、シンプルで ステップバイステップの説明、単純な状況に適用されます。 この記事は管理の専門家を対象としたものではありません。管理の専門家はすでにこれらすべてを知っていますが、読者が自分で MS SQL Server をインストールし、この敵対的なテクノロジの奇跡によってその深層にデータベースを作成できることを前提としています。 1Cデータを強制的に保存できます。
私は、TSQL BACKUP DATABASE コマンド (およびその兄弟の BACKUP LOG) が、基本的に MS SQL Server を DBMS として使用して 1C データベースをバックアップする唯一の手段であると考えています。 なぜ? 一般的にどのようなメソッドがあるかを見てみましょう。
| どうやって | 大丈夫 | ひどく | 合計 |
| dtにアップロード | 非常にコンパクトなフォーマット。 | 形成に時間がかかり、排他的アクセスが必要で、一部の重要でないデータ (ユーザー設定など) は保存されません。 以前のバージョン)、展開するのに長い時間がかかります。 | これはバックアップ方法というよりも、ある環境から別の環境にデータを移動する方法です。 狭いチャンネルに最適です。 |
| コピー MDFファイルそしてldf | 初心者管理者にとって非常にわかりやすい方法です。 | データベース ファイルのロックを解除する必要があります。これは、データベースがオフラインの場合に可能です (take offline コマンド コンテキストメニュー)、切り離される (切り離される) か、サーバーが単に停止されます。 当然、現時点ではユーザーは作業できなくなります。 | この方法は、事故がすでに発生している場合にのみ使用するのが理にかなっています。これにより、回復を試みるときに、少なくとも回復を開始したオプションに戻る機会が得られます。 |
| OSまたはハイパーバイザーを使用したバックアップ | 開発およびテスト環境にとって便利な方法です。 | データの整合性に関して必ずしも友好的であるとは限りません。 リソースを大量に消費する方法。 | 開発での使用が制限される可能性があります。 食品環境では実際的な意味はありません。 |
| MS SQLを使用したバックアップ | ダウンタイムは必要ありません。 事前に心配していれば、任意の時点で完全な状態を復元できます。 優れた自動化。 時間やその他のリソースの点で経済的です。 | あまりコンパクトな形式ではありません。 誰もがこの方法を必要な範囲で使用する方法を知っているわけではありません。 | 食環境のメインツール。 |
組み込みの MS SQL ツールを使用してバックアップを使用する場合の主な問題は、動作原理の基本的な誤解から生じます。 これは部分的には非常な怠惰によって説明され、部分的には「既製のレシピ」レベルでのシンプルでわかりやすい説明の欠如によって説明され(うーん、言っておきますが、私は見つけたことがない)、状況も悪化しています。フォーラム上の「underguru」の神話的なアドバイスによるものです。 怠けてどうするかわかりませんが、バックアップの基本を説明してみます。
何を、なぜ節約するのでしょうか?
遠い昔、遠い銀河系に、1C: Enterprise 7.7 のようなエンジニアリングと会計思想の産物がありました。 どうやら、1C:Enterprise の最初のバージョンが一般的な dbf ファイル形式を使用するように開発されたという事実が原因で、その SQL バージョンでは MS SQL バックアップが完了したとみなすのに十分な情報がデータベースに保存されず、構造が変更されるたびに、完全復旧モデルの動作条件が壊れていたため、バックアップ システムに主な機能を強制的に実行させるには、さまざまな手段を講じる必要がありました。 しかし、バージョン 8 が登場して以来、DBA はようやくリラックスできるようになりました。 標準のバックアップ ツールを使用すると、完全かつ総合的なシステムを作成できます。 バックアップコピー。 登録ログと、フォームの位置の設定 (古いバージョン) などの小さなことだけがバックアップに含まれていません。ただし、このデータが失われてもシステムの機能には影響しません。ただし、データは確かに正しくて便利です。登録ログのバックアップ コピーを作成します。
そもそもなぜバックアップが必要なのでしょうか? うーん。 一見、奇妙な質問。 そうですね、おそらく、第一にシステムのコピーを展開できるようにするため、第二に、障害が発生した場合にシステムを復元できるようにするためでしょうか? 1つ目については同意しますが、2つ目の目的は最初のバックアップ神話です。
バックアップはシステム セキュリティの最後のラインです。データベース管理者がバックアップ コピーから製品システムを復元する必要がある場合、作業の体系化において多くの重大な間違いが発生している可能性があります。 バックアップをデータの整合性を確保する主な方法として扱うことはできません。むしろ、消火システムに近いものです。 消火設備が必要です。 構成され、テストされ、動作する必要があります。 しかし、それがうまくいったとしたら、これ自体が多くの悪影響を伴う深刻な緊急事態であることになります。
バックアップが「平和的」目的にのみ使用されるようにするには、他の手段を使用してパフォーマンスを確保します。
- サーバーの物理的安全を確保します。火災、洪水、電源不良、清掃員、建設作業員、隕石、野生動物はすべて、角を曲がったところでサーバー ルームを破壊するのを待っています。
- 情報セキュリティの脅威に責任を持って対処します。
- システムの変更は上手に行い、それが劣化につながらないことを事前に確認してください。 変化を起こすための計画に加えて、「すべてがうまくいかなかった場合の対処法」についても計画を立てておくことをお勧めします。
- 事故の結果に後から対処するのではなく、テクノロジーを積極的に利用してシステムの可用性と信頼性を高めます。 MS SQL の場合は、次の機能に注意する必要があります。
- MS SQL クラスターの使用 (ただし、正直に言うと、これは 24 時間年中無休を必要としないシステムのデータベース管理者を占有する最も高価で無駄な方法の 1 つだと思います)
- データベース ミラーリング (可用性、パフォーマンス、コストの要件に応じて同期および非同期)
- トランザクションログの配信
- 1C ツール (分散データベース) を使用したレプリケーション
システムの可用性要件とこれらの目的に割り当てられた予算に応じて、ダウンタイムと障害回復時間を 1 ~ 2 桁削減するソリューションを選択することは十分に可能です。 アクセシビリティ テクノロジを恐れる必要はありません。MS SQL の基本知識があれば数日で習得できるほど簡単です。
しかし、何があってもバックアップは必要です。 これは、他のすべての救助手段が失敗した場合に使用できる予備のパラシュートと同じです。 ただし、実際の予備パラシュートと同様に、次のようになります。
- このシステムは事前に正しく専門的に設定されている必要があります。
- システムを使用する専門家は、その使用に関する理論的かつ実践的なスキルを持っている必要があります (定期的に強化されます)。
- システムは最も信頼性が高くシンプルなコンポーネントで構成されている必要があります (これが最後の望みです)。
MS SQL データの保存と処理に関する基本情報
MS SQL のデータは通常、拡張子が mdf または ndf のデータ ファイル (以下、FD と呼びます。この略語は一般的には使用されません。この記事では、あまり一般的ではない略語がいくつかあります) に格納されます。 これらのファイルに加えて、拡張子 .ldf のファイルに保存されるトランザクション ログ (TL) もあります。 初心者の管理者は、パフォーマンスとストレージの信頼性の両方の点で、VT に関して無責任で軽薄であることがよくあります。 これは非常に重大な間違いです。 実際はむしろその逆で、確実に機能するバックアップ システムがあり、システムの復元に多くの時間を割り当てることができる場合は、高速ではあるが信頼性が非常に低い RAID-0 にデータを保存できますが、その場合、データは信頼性が高く生産性の高い別のリソースに保存されます (ただし、RAID-1 上に保存されます)。 なぜそうなるのでしょうか? 詳しく見てみましょう。 このプレゼンテーションは多少簡略化されていますが、最初の理解には十分であることをすぐに予約させてください。
FD はデータを 8 キロバイトのページに保存します (これらは 64 キロバイトのエクステントに結合されますが、これは重要ではありません)。 MS SQL 保証しませんデータ変更コマンドの実行直後に、これらの変更は FD に保存されます。 いいえ、メモリ内のページが「保存が必要」としてマークされているだけです。 サーバーに十分なリソースがある場合、すぐにこのデータはディスク上に配置されます。 さらに、サーバーは「楽観的に」動作するため、トランザクション内でこれらの変更が発生した場合、トランザクションがコミットされる前に変更がディスク上に保存される可能性があります。 つまり、一般に、アクティブな操作中、FD には、キャンセルされるかコミットされるか不明な未完了のデータと未完了のトランザクションが散在します。 特別なコマンド「CHECKPOINT」があります。これは、保存されていないすべてのデータを「今すぐ」ディスクにフラッシュする必要があることをサーバーに指示しますが、このコマンドの範囲は非常に限定的です。 1C はこれを使用しない (私は遭遇したことがありません) ことと、動作中 FD は通常無傷の状態ではないことを理解しておけば十分です。
この混乱に対処するには、VT が必要です。 以下のイベントが記録されます。
- トランザクションの開始とその識別子に関する情報。
- トランザクションのコミットまたはキャンセルの事実に関する情報。
- FD内のデータのすべての変更に関する情報(大まかに言うと、何が起こったのか、何が起こったのか)。
- FD自体またはデータベース構造の変更に関する情報(ファイルの増加、ファイルの減少、ページの割り当てと解放、テーブルとインデックスの作成と削除)
このすべての情報は、発生したトランザクションの識別子を示し、この操作前の状態からこの操作後の状態へ、またはその逆にどのように移行するかを理解するのに十分な量で書き込まれます (例外は部分ロギング回復モデルです)。 。
この情報はすぐにディスクに書き込まれることが重要です。 情報が VT に記録されるまで、コマンドは実行されたとはみなされません。 通常の状況では、VT のサイズが十分で、あまり断片化されていない場合、レコードは小さなレコード (必ずしも 8 kb の倍数ではない) として VT に順次書き込まれます。 トランザクション ログには、回復に実際に必要なデータのみが含まれます。 特に ないどのリクエストテキストが変更を引き起こしたか、このリクエストにはどのような実行計画があったのか、どのユーザーがそれを起動したか、およびリカバリに不要なその他の情報に関する情報が取得されます。 クエリにより、トランザクション ログのデータ構造に関する洞察が得られます。
* から選択::fn_dblog(null,null)
という事実により、 ハードドライブ読み取りおよび書き込みコマンドの混沌としたストリームよりも、シーケンシャル書き込みの方がはるかに効率的に動作します。 SQLコマンド VT への登録が終了するまで待機すると、次の推奨事項が発生します。
ほんのわずかな可能性がある場合でも、製品環境では、VT は、できれば連続記録のアクセス時間を最小限に抑え、信頼性を最大限に高めて、(他のものとは)別個の物理メディアに配置する必要があります。 単純なシステムには、RAID-1 が非常に適しています。
トランザクションがキャンセルされた場合、サーバーはすでに行われたすべての変更を返します。 以前の状態。 それが理由です
MS SQL Server でのトランザクションのキャンセルには、通常、トランザクション自体のデータを変更する操作の合計時間に匹敵する時間がかかります。 取引をキャンセルしないようにするか、できるだけ早くキャンセルの決定を下してください。
サーバーが何らかの理由で予期せず動作を停止した場合、再起動時に、FD 内のどのデータが統合状態 (記録されていないがコミットされたトランザクション、および記録されているがキャンセルされたトランザクション) に対応していないデータが分析され、このデータが修正されます。 したがって、たとえば、大きなテーブルのインデックスの再構築を開始してサーバーを再起動した場合、再起動すると、このトランザクションをロールバックするのにかなりの時間がかかり、このプロセスを中断する方法はありません。 。
VT がファイルの終わりに達するとどうなりますか? それは簡単です - 先頭に空き領域がある場合、ファイルの先頭にある空き領域への書き込みが開始され、 占有スペース。 ループ状の磁気テープのようなもの。 先頭にスペースがない場合、サーバーは通常、トランザクション ログ ファイルの拡張を試みますが、サーバーにとって割り当てられる新しい部分は新しい仮想トランザクション ログ ファイルであり、物理トランザクション ファイル内に多くの部分が存在する可能性があります。 , しかし、これはバックアップとはあまり関係がありません。 サーバーがファイルの拡張に失敗した場合 (ディスク容量が不足しているか、ファイルの拡張が禁止されている設定がある場合)、現在のトランザクションはエラー 9002 でキャンセルされます。
おっと。 鉄道内に常にスペースを確保するには何をする必要がありますか? ここで、バックアップ システムと復旧モデルについて説明します。 トランザクションをキャンセルし、突然のシャットダウンが発生した場合にサーバーの正しい状態を復元するには、最も古いオープン トランザクションの開始から開始して VT にレコードを保存する必要があります。 この最小値は ZhT に書き込まれ、保存されます。 必然的に。 天候、サーバー設定、管理者の希望とは関係ありません。 サーバーは、この情報が存在しないことを許可できません。 したがって、あるセッションでトランザクションを開き、別のセッションで別のアクションを実行すると、トランザクション ログが予期せず終了する可能性があります。 最も古いトランザクションは、DBCC OPENTRAN コマンドで識別できます。 しかし、これは必要最小限の情報にすぎません。 次に何が起こるかは以下によって異なります 回復モデル。 SQL Server には、そのうちの 3 つがあります。
- 単純— 生命に必要な VT の残りだけが保存されます。
- 満杯— 前回のバックアップ以降、VT 全体が保存されます トランザクションログ。 完全バックアップの時点からではないことに注意してください。
- 一括ログ記録— 操作の一部 (通常はごく一部) が非常にコンパクトな形式で記録されます (基本的には、データ ファイルのこれこれのページが変更されたという記録にすぎません)。 それ以外は完全と同じです。
復旧モデルに関しては、いくつかの誤解があります。
- Simple を使用すると、ディスク サブシステムの負荷を軽減できます。。 これは間違いです。 一括ログの場合とまったく同じ量が書き込まれますが、はるかに早い段階で無料とみなされます。
- 一括ログにより、ディスク サブシステムの負荷を軽減できます。。 1C の場合、これはほとんど当てはまりません。 実際、追加のタンバリンダンスを行わずに最小限のロギングに該当する数少ない操作の 1 つは、アップロードからのデータを dt 形式でロードし、テーブルを再構築することです。
- 一括ログ モデルを使用する場合、一部のトランザクションはトランザクション ログ バックアップに含まれず、このバックアップ時の状態を復元することはできません。 これは完全に真実ではありません。 操作のログが最小限であれば、データを含む現在のページがバックアップ コピーに含まれ、トランザクション ログを最後まで「再生」することが可能になります (ただし、トランザクション ログが存在する場合、任意の時点でこれは不可能です)。ログに記録される操作は最小限です)。
1C データベースに一括ログ モデルを使用することはほとんど無意味であるため、これ以上は検討しません。 ただし、フルとシンプルの選択については、次のパートで詳しく検討します。
- トランザクションログ構造
-
- 復旧モデルとトランザクション ログ管理
- トランザクションログ管理
- トランザクション ログ バックアップの使用
シンプル リカバリ モデルと完全リカバリ モデルでのバックアップの仕組み
構成のタイプに基づいて、バックアップ コピーには次の 3 つのタイプがあります。
- 満杯(満杯)
- ディファレンシャル(差分、差分)
- ログ(トランザクション ログのバックアップ コピー。この用語が頻繁に使用されるため、RKZhT と省略します)
ここで混同しないことが重要です。完全復旧モデルと完全バックアップは大きく異なるものです。 混同しないように、以下では復旧モデルには英語の用語を使用し、バックアップの種類にはロシア語の用語を使用します。
フルコピーと差分コピーは、シンプルとフルで同じように機能します。 Simple にはトランザクション ログのバックアップが完全にありません。
完全バックアップ
データベースの状態を特定の時点 (バックアップが開始された時点) に復元できます。 データ ファイルの使用された部分のページごとのコピーと、バックアップの作成中のトランザクション ログのアクティブな部分で構成されます。
差分バックアップ
前回の完全バックアップ以降に変更されたデータのページを保存します。 復元するときは、最初に完全なバックアップ コピーを復元する必要があります (NORECOVERY モードでは、例を以下に示します)。その後、結果として生じる「空白」に後続の差分コピーを適用できますが、もちろん、以前に作成されたものからのみ適用できます。次の完全バックアップ。 これにより、音量を大幅に下げることができます ディスクスペースバックアップコピーを保存します。
重要な点:
- 以前に完全バックアップがなければ、差分コピーは役に立ちません。 したがって、それらを互いに近い場所に保管することをお勧めします。
- 後続の差分バックアップでは、前回の完全バックアップの後に作成された前回の差分バックアップに含まれるすべてのページが保持されます (ただし、内容は異なる可能性があります)。 したがって、完全コピーが再度作成されるまで、後続の差分コピーは以前のものよりも大きくなります (これに違反する場合は、圧縮アルゴリズムのみが原因です)。
- いつかの回復のためには十分です 最後この時点で完全バックアップし、 最後この時点で差分コピーを行います。 中間コピーは回復には必要ありません (ただし、回復の瞬間を選択するために中間コピーが必要になる場合があります)。
RKZhT
一定期間の VT のコピーが含まれます。 通常、最後の RKZhT の瞬間から現在の RKZhT の形成まで。 RKZHT を使用すると、ZHT の復元されたコピーの期間に含まれる任意の時点で、NORECOVERY モードで復元されたコピーから、復元されたバックアップ コピーの間隔に含まれるその後の任意の時点で状態を復元できます。 標準パラメータを使用してバックアップを作成すると、トランザクション ログ ファイル内のスペースが解放されます (最後にトランザクションが開かれるまで)。
明らかに、RKZhT は単純モデルでは意味がありません (その場合、ZhT には、最後に閉じられていないトランザクションの瞬間からの情報のみが含まれます)。
RKZhT を使用する場合、重要な概念が生じます - RKZhTの連続チェーン。 このチェーンは、このチェーンのバックアップ コピーが失われるか、データベースを単純に変換してから元に戻すことによって中断される可能性があります。
注意: RKZhT のセットは、連続チェーンでない場合は本質的に役に立たず、最後に成功した完全バックアップまたは差分バックアップの開始点は次のとおりである必要があります。 内部このチェーンの期間。
よくある誤解と通説:
- 「RKZhT には、前回の完全バックアップまたは差分バックアップの瞬間からのトランザクション ログ データが含まれています。」いいえ、そうではありません。 RKZhT には、前回の RKZhT とその後の完全バックアップの間に、一見すると役に立たないデータも含まれています。
- 「完全バックアップまたは差分バックアップにより、トランザクション ログ内のスペースが解放されます。」いいえ、そうではありません。 完全バックアップと差分バックアップは RKZhT チェーンには影響しません。
- VT は定期的に手動で洗浄し、縮小し、細断する必要があります。いいえ、それは必要ではありませんし、逆に望ましくありません。 RCVT 間の VT を解放すると、修復に必要な RCVT チェーンが切断されます。 また、ファイルを継続的に縮小/拡張すると、物理的および論理的な断片化が発生します。
シンプルな仕組み
1000 GB のデータベースがあるとします。 データベースは毎日 2 GB ずつ増加し、10 GB の古いデータが変更されます。 以下のバックアップが作成されています
- 2 月 1 日 0:00 の F1 の完全コピー (ボリューム 1000 GB、図をわかりやすくするために圧縮は考慮されていません)
- 2月2日0時からのD1.1の差分コピー(ボリューム12GB)
- 2月3日0時からD1.2の差分コピー(容量19GB)
- 2月4日0時からのD1.3の差分コピー(容量25GB)
- 2月5日0時からのD1.4の差分コピー(ボリューム31GB)
- 2月6日0時からの差分コピーD1.5(容量36GB)
- 2月7日0時からのD1.6の差分コピー(ボリューム40GB)
- 2 月 8 日 0:00 の F2 の完全コピー (ボリューム 1014 GB)
- 2月9日0時からのD2.1の差分コピー(ボリューム12GB)
- 2月10日0時からのD2.2の差分コピー(ボリューム19GB)
- 2月11日0時からのD2.3の差分コピー(容量25GB)
- 2月12日0時からのD2.4の差分コピー(ボリューム31GB)
- 2月13日0時からの差分コピーD2.5(容量36GB)
- 2月14日0時よりD2.6の差分コピー(ボリューム40GB)
このセットを使用すると、2月1日から2月14日までの任意の日の0時にデータを復元できます。 これを行うには、2 月 1 日から 7 日までの週の F1 の完全コピー、または 2 月 8 日から 14 日までの F2 の完全コピーを取得し、NORECOVERY モードで復元してから、目的の日の差分コピーを適用する必要があります。
完全な仕組み
前の例と同じ完全バックアップと差分バックアップのセットを用意してみましょう。 これに加えて、次の RKZhT があります。
- 1月31日12時から2月2日12時までの期間 RKZhT1(約30GB)
- RKZhT2 2月2日12時~2月4日12時までの期間(約30GB)
- RKZhT3 2月4日12:00~2月6日12:00の期間(約30GB)
- 2月6日12時から2月7日12時までの期間 RKZhT4(約30GB)
- 2月8日12時から2月10日12時までの期間 RKZhT5(約30GB)
- 2月10日12時から2月12日12時までの期間 RKZhT6(約30GB)
- RKZhT 7 2月12日12:00~2月14日12:00の期間(約30GB)
- 2月14日12時から2月16日12時までの期間 RKZhT8(約30GB)
ご注意ください:
- RKZhT のサイズはほぼ一定になります。
- バックアップは、差分バックアップまたは完全バックアップよりも少ない頻度で作成できます。または、より頻繁にバックアップを作成でき、その場合はサイズが小さくなります。
- 最も早い完全なコピーが得られる 2 月 1 日の 0:00 から 2 月 16 日の 12:00 まで、システム状態を任意の時点に復元できるようになりました。
最も単純なケースでは、以下を復元する必要があります。
- リカバリ前の最後の完全コピー
- リカバリ前の最後の差分コピー
- 最後の差分コピーの瞬間から復元の瞬間までのすべての RKZhT
- 2 月 8 日 0:00 からの F2 の完全コピー
- 2月10日0時からの差分コピーD2.2
- 1月10日12時から2月12日12時までの期間はRKZhT6
まず、F2 が復元され、次に D2.2、次に RKZhT 6 が 2 月 10 日 13:13:13 まで復元されます。 しかし、フル モデルの大きな利点は、最後の完全コピーまたは差分コピーを使用するか、最後のコピーではなく使用するかを選択できることです。 たとえば、D2.2 のコピーが破損していることが判明し、2 月 10 日 13:13:13 より前の時点に復元する必要がある場合、シンプル モデルの場合、これは、D2.2 のコピーのみを復元できることを意味します。瞬間D2.1までのデータ。 フル - 「DON"T PANIC」では、次のオプションがあります。
- 2 月 10 日の 13:13:13 まで、F2、次に D2.1、次に RKZHT 5、次に RKZHT 6 を復元します。
- 2 月 10 日の 13:13:13 まで、F2、次に RKZHT 4、次に RKZHT 5、次に RKZHT 6 を復元します。
- あるいは、F1 を復元して、2 月 10 日の 13:13:13 まで RKZhT 6 までのすべての RKZhT を実行することもできます。
ご覧のとおり、フルモデルではより多くの選択肢が与えられます。
さて、私たちが非常に狡猾であると想像してみましょう。 そして、障害が発生する数日前 (2 月 10 日 13:13:13)、障害が発生することがわかっています。 隣接するサーバー上の完全バックアップからデータベースを復元し、差分コピーまたは RKZhT を使用して後続の状態をロールアップする機会を残します。つまり、NORECOVERY モードのままにします。 そして毎回、RKZhT の形成直後にそれをこの予備ベースに適用し、NORECOVERY モードのままにします。 おお! なんと、巨大なデータベースを復元するのではなく、データベースの復元にかかる時間はわずか 10 ~ 15 分になります。 おめでとうございます。ダウンタイムを削減する方法の 1 つであるログ配布を再発明しました。 この方法でデータを期間ごとに 1 回ではなく常に転送すると、ミラーリングが行われます。ソース ベースがミラー ベースが更新されるまで待機する場合、これは同期ミラーリングです。待機しない場合は、非同期ミラーリングになります。 。
ファンドについて詳しくは 高可用性ヘルプで読むことができます:
- 高可用性 (データベース エンジン)
- 高可用性ソリューションを理解する
- 高いレベルのアクセシビリティ。 インタラクションとコラボレーション
バックアップに関するその他の考慮事項
理論に飽きていて、バックアップ設定を試してみたいと思っている場合は、このセクションを飛ばしても問題ありません。
ファイルグループ
1C:エンタープライズは基本的にファイル グループの操作方法を知りません。 単一のファイル グループがあり、それだけです。 実際、プログラマーや MS SQL データベース管理者は、いくつかのテーブル、インデックス、さらにはテーブルとインデックスの一部を別のファイル グループ (最も単純なバージョンでは別のファイル) に配置することができます。 これは、一部のデータへのアクセスを高速化する (非常に高速なメディアにデータを配置する) か、逆に速度を犠牲にして安価なメディア (たとえば、ほとんど使用されていないが大量のデータ) にデータを配置するために必要です。 ファイル グループを操作する場合、それらのバックアップ コピーを個別に作成したり、個別に復元したりすることもできますが、すべてのファイル グループを 1 つのポイントに「追いつく」必要があることを考慮する必要があります。 RKZhT。
データファイル
ユーザーが異なるファイル グループへのデータの配置を管理している場合、ファイル グループ内に複数のファイルがある場合、MS SQL Server はデータをそれらのファイルに個別にプッシュします (ファイルのボリュームが等しい場合、均等に試行されます)。 アプリケーションの観点から見ると、これは I/O 操作を並列化するために使用されます。 しかし、バックアップの観点から見ると、別の点があります。 SQL 2008 以前の非常に大規模なデータベースの場合、完全バックアップに連続したウィンドウを割り当てるのが一般的な問題であり、このバックアップの宛先ディスクがそれに対応できない可能性がありました。 最も 簡単な方法でこの場合、各ファイル (またはファイル グループ) を独自のウィンドウにバックアップすることになります。 現在、バックアップ圧縮が積極的に普及しているため、この問題は少なくなりましたが、この手法は依然として覚えておくことができます。
バックアップの圧縮
MS SQL Server 2008 では、スーパーメガウルトラ機能が導入されました。 今後も永久に、バックアップをオンザフライで生成するときに圧縮できます。 これにより、1C データベースのバックアップのサイズが 5 ~ 10 分の 1 に削減されます。 また、通常、ディスク サブシステムのパフォーマンスが DBMS のボトルネックであることを考えると、これによりストレージのコストが削減されるだけでなく、バックアップが大幅に高速化されます (ただし、プロセッサの負荷は増加しますが、通常、プロセッサの能力は DBMS 上で十分です)。 DBMS サーバー)。
2008 バージョンではこの機能が Enterprise エディション (非常に高価) でのみ利用可能でしたが、2008 R2 ではこの機能が Standard バージョンにも提供されました。これは非常に喜ばしいことです。
圧縮設定については、以下の例では説明していませんが、無効にする特別な理由がない限り、バックアップ圧縮を使用することを強くお勧めします。
1 つのバックアップ ファイル - 多数の内部ファイル
実際、バックアップは単なるファイルではなく、多くのバックアップを保存できるかなり複雑なコンテナです。 このアプローチには非常に古い歴史があります (私は個人的にバージョン 6.5 から観察しています) が、現時点では「通常の」データベース、特に 1C データベースの管理者にとって、「1 つのバックアップ コピー - 1 つのバックアップ コピー」を使用しない重大な理由はありません。ファイル」アプローチ。 一般的な開発では、複数のバックアップ コピーを 1 つのファイルに入れる機能を研究すると便利ですが、ほとんどの場合、それを使用する必要はありません (または、使用する必要がある場合、管理者志望者の瓦礫を整理することになります)この機会を無条件に利用した者)。
複数のミラーコピー
SQL Server にはもう 1 つの優れた機能があります。 複数の受信機で並行してバックアップ コピーを作成できます。 どうやって 最も単純な例、1つのコピーをダンプできます ローカルディスクそして同時に折ります ネットワークリソース。 ローカル コピーは、ローカル コピーからの復元がはるかに速いため便利です。 リモートコピーただし、メイン データベース サーバーの物理的な破壊にははるかによく耐えます。
バックアップ体制の例
理論は十分だ。 このキッチン全体が機能することを実践して証明する時が来ました。
メンテナンス プランによる一般的なサーバー予約の設定
このセクションは、説明付きの既製レシピの形式で構成されています。 このセクションは非常に退屈で、写真があるため長いので、読み飛ばしても大丈夫です。
サービスプラン作成ウィザードの使用
TSQL スクリプトを使用したサーバー バックアップのセットアップ、いくつかの機能の例
他に何が必要なのかという疑問がすぐに生じます。 すべてを設定しただけで、すべてが時計のように機能しているように見えますか? なぜわざわざさまざまな種類のスクリプトを使用するのでしょうか? サービス プランでは次のことは許可されません。
- ミラーバックアップを使用する
- サーバー設定とは異なる圧縮設定を使用する
- 新たな状況に柔軟に対応できない(エラー処理機能がない)
- セキュリティ設定を柔軟に使用できない
- サービス プランは、展開 (および維持) するのに非常に不便です。 大量のサーバー (おそらくすでに 3 ~ 4 台)
以下は一般的なバックアップ コマンドです。
完全バックアップ
既存のファイル (存在する場合) を上書きし、検証を行う完全バックアップ チェックサム録音前のページ。 バックアップを作成するとき、進行状況のすべての割合がカウントされます
データベースをディスクにバックアップ = N"C:\Backup\mydb.bak"、初期化、フォーマット、統計 = 1、チェックサムを使用します
差分バックアップ
同様に - 差分コピー
データベースをディスクにバックアップ = N"C:\Backup\mydb.diff" を使用して ディファレンシャル、初期化、フォーマット、統計 = 1、チェックサム
RKZhT
トランザクションログのバックアップ
ログをディスクにバックアップ = N"C:\Backup\mydb.trn" WITH INIT, FORMAT
ミラーバックアップ
多くの場合、一度に 1 つのバックアップ コピーを作成するのではなく、2 つのバックアップ コピーを作成すると便利です。 たとえば、1 つをサーバー上でローカルに保存し (すぐに使えるように)、2 つ目はすぐに物理的にリモートに形成され、ストレージへの悪影響から保護されます。
データベースをディスクにバックアップ = N"C:\Backup\mydb.bak", ミラーリング DISK = N"\\safe-server\backup\mydb.bak" WITH INIT, FORMAT
見落とされがちな重要な点です。MSSQL Server プロセスを起動するユーザーは、リソース "\\safe-server\backup\" にアクセスできる必要があります。アクセスできない場合、コピーは失敗します。 MSSQL Server がシステムに代わって起動される場合、アクセスはドメイン ユーザー "server_name$" に与えられる必要がありますが、特別に作成されたユーザーに代わって実行されるように MS SQL を正しく構成することをお勧めします。
MIRROR TO を指定しない場合は、2 つのミラー コピーではなく、インターリーブの原則に従って 2 つのファイルに分割された 1 つのコピーになります。 そして、それらのそれぞれは個別には役に立ちません。
以前の資料で Microsoft SQL Server データベースのバックアップの問題についてはすでに触れましたが、読者の反応は、理論的な部分をさらに深く研究した本格的な資料を作成する必要があることを示しています。 確かに、以下に重点を置いて実施されました。 実践的な指示この記事では、バックアップを簡単に設定できますが、特定の設定を選択する理由については説明していません。 このギャップを修正してみましょう。
復旧モデル
バックアップを設定する前に、復旧モデルを選択する必要があります。 最適な選択をするには、回復要件とデータ損失の重要性を評価し、特定のモデルの実装にかかるオーバーヘッド コストと比較する必要があります。
ご存知のとおり、MS SQL データベースは、データベース自体とそのトランザクション ログの 2 つの部分で構成されています。 データベースには現時点のユーザー データとサービス データが含まれ、トランザクション ログには一定期間のデータベースに対するすべての変更履歴が含まれます。トランザクション ログを使用すると、データベースの状態を任意の時点にロールバックできます。
運用環境で使用できる復旧モデルは 2 つあります。 シンプルで完全な。 が付いたモデルもあります 不完全なロギングただし、ベースを復元する必要がない、大規模な大量運用期間中に完全モデルへの追加としてのみ推奨されます。 ある瞬間時間。
シンプルモデルデータベースのみのバックアップを提供します。したがって、バックアップが作成された時点のデータベースの状態のみを復元できます。最後のバックアップの作成から障害が発生するまでのすべての変更は失われます。 同時に 簡単な回路オーバーヘッドが低い: データベースのコピーを保存するだけでよく、トランザクション ログは自動的に切り捨てられ、サイズは増加しません。 また、回復プロセスは最も簡単で、時間もかかりません。
フルモデルデータベースを任意の時点に復元できますが、データベースのバックアップに加えて、復元が必要な期間全体のトランザクション ログのコピーを保存する必要があります。 データベースを積極的に操作する場合、トランザクション ログのサイズ、つまりアーカイブのサイズが大きくなる可能性があります。 回復プロセスもはるかに複雑で時間がかかります。
復旧モデルを選択するときは、復旧のコストとバックアップ コピーの保存にかかるコストを比較し、復旧を実行する担当者の可用性と資格も考慮する必要があります。 完全なモデルを使用した修復には、担当者に特定の資格と知識が必要ですが、単純なスキームの場合は指示に従うだけで十分です。
少量の情報が追加されたデータベースの場合は、次のような単純なモデルを使用する方が収益性が高い場合があります。 高周波これにより、失われたデータを手動で入力することで、すぐに回復して作業を続行できるようになります。 完全なモデルは主に、データ損失が許容できない場合に使用する必要があります。 回復の可能性多大な費用がかかります。
バックアップの種類
データベースの完全なコピー- その名前が示すように、データベースの内容と、バックアップが作成された時点のアクティブなトランザクション ログの一部 (つまり、現在および未完了のすべてのトランザクションに関する情報) を表します。 データベースをバックアップ作成時の状態に完全に復元できます。
デルタデータベースコピー- フルコピーには重大な欠点が 1 つあります。それは、すべてのデータベース情報が含まれていることです。 バックアップを頻繁に作成する必要がある場合、ストレージの大部分が同じデータで占有されるため、ディスク領域の無駄な使用の問題が直ちに生じます。 この欠点を解消するには、前回のデータベース以降に変更された内容のみを含むデータベースの差分コピーを使用します。 フルコピー情報。
 差分コピーは前回のデータですのでご注意ください 満杯コピーする、つまり 後続の差分コピーには前のコピーのデータが含まれており (ただし、変更される可能性があります)、コピーのサイズは常に増加します。 復元するには、1 つの完全コピーと 1 つの差分コピー (通常は最後のコピー) で十分です。 差分コピーの数は、サイズの増加に基づいて選択する必要があります。差分コピーのサイズが完全コピーの半分のサイズに等しくなったら、新しい完全コピーを作成するのが合理的です。
差分コピーは前回のデータですのでご注意ください 満杯コピーする、つまり 後続の差分コピーには前のコピーのデータが含まれており (ただし、変更される可能性があります)、コピーのサイズは常に増加します。 復元するには、1 つの完全コピーと 1 つの差分コピー (通常は最後のコピー) で十分です。 差分コピーの数は、サイズの増加に基づいて選択する必要があります。差分コピーのサイズが完全コピーの半分のサイズに等しくなったら、新しい完全コピーを作成するのが合理的です。
トランザクションログのバックアップ- 完全復旧モデルにのみ適用され、前のコピーが作成された瞬間から始まるトランザクション ログのコピーが含まれます。

次の点に留意することが重要です。トランザクション ログのコピーはデータベースのコピーとはまったく関係がなく、以前のコピーの情報も含まれていないため、データベースを復元するには、必要な期間のコピーの切れ目のないチェーンが必要です。データベースの状態をロールバックできるようになります。 この場合、最後にコピーが成功した時点がこの期間内である必要があります。
上の図を見てみましょう。ログ ファイルの最初のコピーが失われた場合、データベースの状態は完全コピーの時点でのみ復元できます。これは単純な復旧モデルと同様です。データベースのコピーの前のものから始まるログ コピーのチェーンが連続している場合に限り、次の差分 (または完全) コピーの後のみ、データベースの状態をいつでも復元できます (図内) - 3 番目以降)。
トランザクションログ
回復と割り当てのプロセスを理解するため さまざまな種類バックアップの場合は、トランザクション ログの構造と操作を詳しく調べる必要があります。 トランザクションは、意味をなす最小限の論理操作であり、完全に完了する必要があります。 このアプローチでは、操作の中間状態は受け入れられないため、あらゆる状況でデータの整合性と一貫性が保証されます。 トランザクション ログは、データベース内の変更を制御するために使用されます。
何らかの操作が実行されると、トランザクションの開始に関するレコードがトランザクション ログに追加され、各レコードには途切れることのないシーケンスから一意の番号 (LSN) が割り当てられ、データが変更されると、対応するエントリがログに作成されます。操作が完了すると、トランザクションの終了(コミット)を示すマークがログに表示されます。
 各起動時に、システムはトランザクション ログを分析し、コミットされていないトランザクションをすべてロールバックすると同時に、ログに記録されたもののディスクに書き込まれなかった変更をロールバックします。 これにより、バックアップ電源システムがない場合でも、データの整合性を気にせずにキャッシュと遅延書き込みを使用できるようになります。
各起動時に、システムはトランザクション ログを分析し、コミットされていないトランザクションをすべてロールバックすると同時に、ログに記録されたもののディスクに書き込まれなかった変更をロールバックします。 これにより、バックアップ電源システムがない場合でも、データの整合性を気にせずにキャッシュと遅延書き込みを使用できるようになります。
アクティブなトランザクションが含まれ、データ回復に使用されるログの部分は、ログのアクティブ部分と呼ばれます。 これは、最小回復番号 (MinLSN) と呼ばれる番号で始まります。
最も単純なケースでは、MinLSN は最初の保留中のトランザクションのレコード番号です。 上の図を見ると、青色のトランザクションを開くと 321 に等しい MinLSN が取得されます。レコード 324 で修正された後、MinLSN 番号は 323 に変更されます。これは、緑色のトランザクションではなく、緑色のトランザクションの番号に対応します。まだコミット済みのトランザクションです。
実際には、すべてがもう少し複雑です。たとえば、クローズされた青色のトランザクションのデータがまだディスクにフラッシュされていない可能性があり、MinLSN を 323 に移動すると、この操作の回復が不可能になります。 このような状況を回避するために、コントロール ポイントの概念が導入されました。 次の条件が発生すると、チェックポイントが自動的に作成されます。
- CHECKPOINT ステートメントを明示的に実行する場合。 チェックポイントは、現在の接続データベースでトリガーされます。
- 操作を実行するときなど、最小限のログを使用してデータベースで操作を実行するとき 大量コピー一括ログ復旧モデルの対象となるデータベースの場合。
- ALTER DATABASE ステートメントを使用してデータベース ファイルを追加または削除するとき。
- SHUTDOWN ステートメントを使用して SQL Server のインスタンスを停止するとき、または SQL Server サービス (MSSQLSERVER) を停止するとき。 どちらの場合も、SQL Server インスタンス内のデータベースごとにチェックポイントが作成されます。
- SQL Server のインスタンスがデータベースの回復時間を短縮するために、各データベースに自動チェックポイントを定期的に作成する場合。
- データベースのバックアップを作成するとき。
- データベースのシャットダウンが必要なアクションを実行するとき。 例としては、AUTO_CLOSE パラメータを ON に設定し、データベースへのユーザーの最後の接続を閉じることや、データベースの再起動が必要なデータベース設定の変更などが挙げられます。
どのイベントが最初に発生したかに応じて、MinLSN はチェックポイント レコード番号または最も古い保留中のトランザクションの開始のいずれかに設定されます。
トランザクションログの切り捨て
トランザクション ログは、他のログと同様に、古いエントリを定期的に消去する必要があります。そうしないと、ログが増大して利用可能なスペースをすべて占有してしまいます。 データベースを積極的に操作している場合、トランザクション ログのサイズがデータベースのサイズを大幅に超える可能性があることを考慮すると、この問題は多くの管理者にとって重要です。
物理的には、トランザクション ログ ファイルは仮想ログのコンテナであり、ログが増大するにつれて順次いっぱいになります。 MinLSN エントリを含む論理ログはアクティブなログの始まりであり、その前の論理ログは非アクティブであり、アクティブなログには必要ありません。 自動回復基地。
 選択した場合 シンプルなモデルリカバリ後、論理ログが物理ファイルの 70% に等しいサイズに達すると、ログの非アクティブな部分が自動的にクリアされます。 切り捨て。 ただし、これによって物理ログ ファイルは縮小されません。論理ログのみが切り捨てられ、この操作後に再利用できるようになります。
選択した場合 シンプルなモデルリカバリ後、論理ログが物理ファイルの 70% に等しいサイズに達すると、ログの非アクティブな部分が自動的にクリアされます。 切り捨て。 ただし、これによって物理ログ ファイルは縮小されません。論理ログのみが切り捨てられ、この操作後に再利用できるようになります。
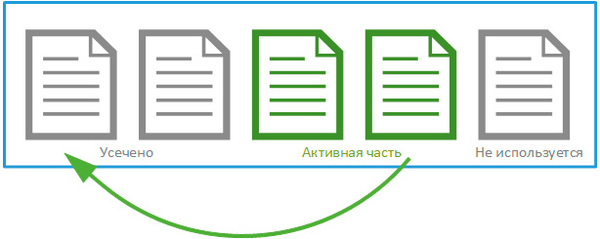
トランザクションの数が多く、物理ファイル サイズの 70% に達するまでに非アクティブな論理ログがなくなると、物理ファイル サイズが増加します。
 したがって、単純な復旧モデルを使用したトランザクション ログ ファイルは、ログのアクティブな部分全体が確実に含まれるまで、データベースの操作アクティビティに応じて増大します。 その後、その成長は止まります。
したがって、単純な復旧モデルを使用したトランザクション ログ ファイルは、ログのアクティブな部分全体が確実に含まれるまで、データベースの操作アクティビティに応じて増大します。 その後、その成長は止まります。
完全なモデルでは、完全にバックアップされるまで、ログの非アクティブな部分を切り捨てることはできません。 トランザクション ログがバックアップされ、チェックポイントが作成されている場合、ログの切り捨てが発生します。
フル モデルでのトランザクション ログ バックアップの構成が不適切であると、ログ ファイルの増大が制御不能になる可能性があり、これは経験の浅い管理者にとって問題となることがよくあります。 また、トランザクション ログを手動で切り詰めるというアドバイスもよく見かけます。 完全復旧モデルでは、これは断固として実行すべきではありません。これは、ログ コピーのチェーンの整合性に違反し、コピーが作成された時点でのみデータベースを復元できるためです。これは、単純なモデルに対応します。 。
この場合、記事の冒頭で述べたことを思い出してください。完全なモデルのコストが修復のコストを超える場合は、単純なモデルを優先する必要があります。
シンプルな復旧モデル
必要な最低限の知識を取得したので、復旧モデルのより詳細な検討に進むことができます。 簡単なことから始めましょう。 障害が発生した時点で、完全コピーが 1 つと差分コピーが 2 つあったとします。
 バックアップは 1 日 1 回実行され、最後のコピーは 21 日から 22 日の夜に作成されました。 この障害は、22 日の夜、次のコピーが作成される前に発生します。 この場合、完全な差分コピーと最後の差分コピーを順番に復元する必要があり、最終営業日のデータは失われます。 何らかの理由で 21 日のコピーも破損していることが判明した場合は、前のコピーを復元して、さらに 1 日の作業を失うことができますが、同時に 20 日のコピーが破損しても作業が妨げられることはありません。対応するコピーが利用可能になった 21 日の夜にデータを正常に復元することはできませんでした。
バックアップは 1 日 1 回実行され、最後のコピーは 21 日から 22 日の夜に作成されました。 この障害は、22 日の夜、次のコピーが作成される前に発生します。 この場合、完全な差分コピーと最後の差分コピーを順番に復元する必要があり、最終営業日のデータは失われます。 何らかの理由で 21 日のコピーも破損していることが判明した場合は、前のコピーを復元して、さらに 1 日の作業を失うことができますが、同時に 20 日のコピーが破損しても作業が妨げられることはありません。対応するコピーが利用可能になった 21 日の夜にデータを正常に復元することはできませんでした。
完全復旧モデル
完全復旧モデルを使用した同様の状況を考えてみましょう。 また、完全 + 差分の原則を使用して毎日バックアップを作成し、トランザクション ログも 1 日に数回コピーします。
 この場合の回復プロセスはより複雑になります。 最初のステップは、ログの末尾 (赤で表示) を手動でバックアップすることです。 最後のコピーが作成されてから事故が発生するまでのログの一部。
この場合の回復プロセスはより複雑になります。 最初のステップは、ログの末尾 (赤で表示) を手動でバックアップすることです。 最後のコピーが作成されてから事故が発生するまでのログの一部。
これを行わないと、トランザクション ログの最後のコピーが作成された時点の状態にのみデータベースを復元できます。
この場合、前日のログ コピー ファイルが損傷しても、データベースの現在の状態を復元することはできますが、復元できるのは最後のコピーが作成された時点までに制限されます。 現在の日々。
次に、最後のバックアップ後に作成されたログの完全コピーと差分コピー、およびコピーのチェーンを順番に復元します。最後に復元するものは、ログの最後のフラグメントのコピーであり、データベースを正しく復元する機会が得られます。事故発生時、または事故に先立つ任意の事故時。
最後の差分コピーが破損した場合、単純なモデルの場合、さらに 1 日の作業が失われることになります。完全なモデルでは、最後から 2 番目のコピーを復元できます。その後、トランザクション チェーン全体を復元する必要があります。最後から 2 番目のコピーの瞬間から障害が発生するまでのログ コピー。 リカバリの深さは、ログの連続チェーンの深さにのみ依存します。
一方、トランザクション ログ コピーの 1 つ (たとえば、最後から 2 番目のコピー) が破損した場合、データを復元できるのは、最後のバックアップの時刻 + 無傷のログ コピー チェーンの期間までのみです。 たとえば、ログが 12 時、14 時、16 時に作成され、14 時に作成されたログが破損している場合、毎日のコピーがあれば、連続チェーンの終わりまでデータベースを復元できます。 12時まで。
「情報を所有する者は世界を所有する」 - メイヤー・アムシェル・ロスチャイルド
あらゆるビジネスにおいて最も価値のある資産は情報です。 情報の損失は、主に財務上の予期せぬ結果を招く可能性があります。 したがって、IT スペシャリストの主なタスクの 1 つは、IT インフラストラクチャ全体のバックアップです。 これは MS SQL Server データベースにも当てはまります。
使用するデータベース内の情報の安全性を確保し、機能を復元する時間を短縮するには、SQL サーバーのバックアップを定期的に実行する必要があります。
簡単な例を見てみましょう。データベースのバックアップを別のディスクに構成する必要があります。
解決:
- オープニング Microsoft SQL Server管理スタジオ。 右側のナビゲーション メニューでタブを開きます "コントロール"。 そこにタブが表示されます 「サービスプラン」。 右クリック→ 「サービスプランの作成」そして計画に名前を付けます (図 1):
図 1 新しいサービス プランの作成。
2. ツールバーにタスクを追加します 「データベースのバックアップ」(図2):

図2 「データベースバックアップ」タスクの追加。
3. 作成したタスクを右クリック→ "変化"(図3):

4. タスクのプロパティ ウィンドウで、バックアップの種類 (私の場合はフル) を選択し、目的のデータベース (ka_cons を使用)、バックアップのディレクトリ、バックアップ コピーの整合性をチェックする機能、およびバックアップ コピーの圧縮オプションを選択します (図 4-6):

図4 バックアップの種類 - フル。

図5 バックアップするデータベースの選択。

図6 バックアップ用のディレクトリを定義し、整合性と圧縮率をチェックします。
5. 右側のサービス プラン設定パネル。 ボタンを押してください "スケジュール"(図7):

6. 必要なスケジュールを設定し、 "わかりました"(図8):

図 8 バックアップ スケジュールの設定。
7. サービス プランを保存します (図 9)。

図 9 保守計画の保存。
スケジュールされたデータベースの完全バックアップが構成されています。
-
 2015 年 4 月 17 日Windows 用の無料プログラムを無料でダウンロード Google Earth アプリケーションをダウンロード
2015 年 4 月 17 日Windows 用の無料プログラムを無料でダウンロード Google Earth アプリケーションをダウンロード -
 2015 年 4 月 17 日電気工学受験票 つま先の試験問題
2015 年 4 月 17 日電気工学受験票 つま先の試験問題 -
 2015 年 4 月 17 日エラー 1 秒 8 のナビゲーション ウィンドウ
2015 年 4 月 17 日エラー 1 秒 8 のナビゲーション ウィンドウ -
 2015 年 4 月 17 日ISDN と比較した Skype プロトコルの代替実装 Skype プログラム
2015 年 4 月 17 日ISDN と比較した Skype プロトコルの代替実装 Skype プログラム





